

Another cluster of fake scientific papers has been discovered, this time primarily about electronic medical devices and software. A group of three researchers has published an exposé of papers in which ordinary terms like artificial intelligence and facial recognition are replaced with bizarre alternatives auto-generated from a thesaurus. This appears to be an attempt to hide plagiarism, AI-driven paper auto-generation and/or “paper mill” activity, in which companies generate forged research and sell it to (pseudo-)scientists who want to get promoted.
| GENUINE TERM | AUTO-GENERATED REPLACEMENT |
|---|---|
| Big data | Colossal information |
| Facial recognition | Facial acknowledgement |
| Artificial intelligence | Counterfeit consciousness |
| Deep neural network | Profound neural organization |
| Cloud computing | Haze figuring |
| Signal to noise | Flag commotion |
| Random value | Irregular esteem |
Often these papers originate in China, where the CCP has mandated that every single medical doctor must publish research papers to get promoted (i.e. in their non-existent spare time). If you’re new to this topic, my previous article on Photoshopped images and impossible numbers in scientific papers provides some background along with an entertaining begging letter from a Chinese doctor who got busted.
Most of the bad science covered on the Daily Sceptic is of the intellectually dishonest kind: an absurd assumption here, ignored evidence over there. Sometimes professors – like those at Imperial College London – turn out to be incapable of using computers correctly and are presenting internal data corruption in their models as ‘evidence’, a problem I wrote about in my first article for this site. While these papers are extremely serious for public trust in science, especially given the huge impact they have had, there are even worse problems lurking in the depths of the literature. The biggest is probably 100% fake papers that report on non-existent experiments, often in obscure areas of Alzheimer’s research or oncology.
Corrupt journals and their explanations
In their article (an unpublished pre-print), Cabanac, Labbé and Magazinov zoom in on a journal called “Microprocessors and microsystems“, published since 1976 by Elsevier. They document a sudden step-change in the quantity of papers being published around the end of 2019, with another massive jump at the start of 2021.
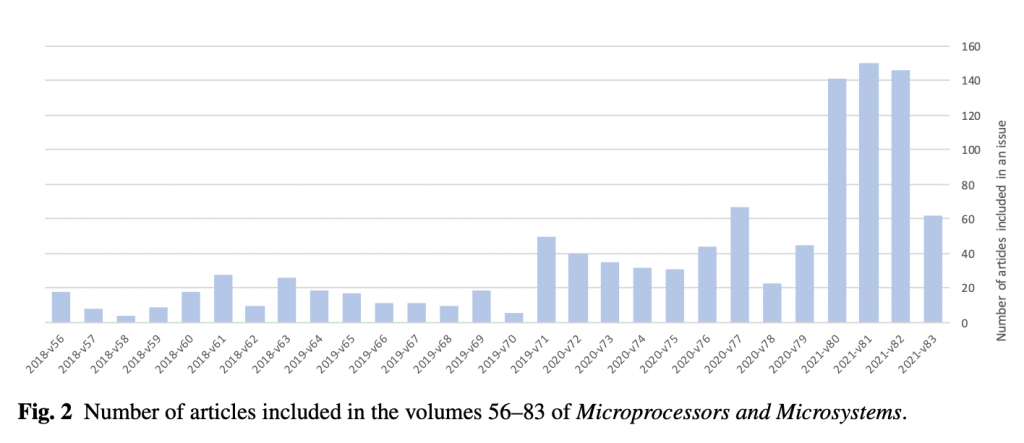
While even famous journals like Nature frequently publish intellectually dishonest nonsense, corrupt scientists seem to focus on finding especially weakly run journals and entirely subverting them. This allows them to publish papers in which the language doesn’t even make grammatical sense, let alone display intellectual rigour. Many of the papers feature not only bizarre substitutions but also plagiarised text, stolen images and of course the inevitable Photoshops.
Exactly how this process occurs is unclear because one of the most problematic aspects of the fake science phenomenon is that when asked to investigate, journals and authors invariably try to BS their way out of it. For example, last time the excuse presented by the NHS for a clearly Photoshopped image was that the patient had “worn the same shirt”, even though literally anyone could see that claim was false. And so it is again. This time the excuse we’re presented with is that:
“Unfortunately, due to a configuration error in the editorial system, the Editor in Chief or designated Handling Editor did not receive these papers for approval, as per the journal’s standard workflow. This configuration error was a temporary issue due to system migration and was corrected as soon as it was discovered“
– Microprocessors and microsystems
In other words, Elsevier is arguing that they are capable of publishing scientific papers that literally nobody has read at all, and capable of doing this for multiple entire editions of their journals without anybody noticing. Microsystems and microprocessors costs $1,893 a year for an institutional subscription, but it’s run with a less rigorous review process than this website. Is that really credible? It hardly matters; no matter what perspective you look at it from their explanation is damning. Either it’s a lie (as explanations of scientific misconduct have often been in the past), or it’s true and Elsevier are saying that they’ve been charging thousands of dollars a year for a non-existent editorial service. Remember that it’s ultimately taxpayers who fund this via government research budgets.
Medical corruption spreads to other fields
This journal is suspicious in another way: despite theoretically being about embedded micro-controllers, a quick review of the articles shows that many of them have nothing to do with this topic and in fact some of them are clearly medical papers, e.g. the last issue contains articles on watermarking algorithms for medical images. Although related to computer science, that is not related to this specific sub-field. In April what is clearly a purely medical paper was published by some nurses in China. It appears to be something related to MRI scans. I say “appears” because the paper is so garbled that it’s basically unintelligible. The final sentence of the abstract says:
“MRI is more research to enable a normal identification from pathological conditions required to provide a diagnostic reference value, to be used for functional PHV evaluation potential shows.”
This sentence doesn’t seem to contain much real meaning so it’s questionable whether it’s explainable as a bad auto-translation. The paper also passes off a circuit diagram of a simple water leak detector downloaded from a western website as an “image detection sensor using intervention after heart valve replacement”. As is often the case with investigations into scientific integrity, everything looks roughly right from a distance until you sit down and start reading carefully, at which point it all falls apart.
It’s worth stressing that this problem isn’t limited to one or two journals, nor is it exclusive to Chinese authors. A quick search on Google Scholar for “counterfeit consciousness” or “profound neural organisation” shows large numbers of results in many different journals, with Indian names also being quite prevalent.
Where do these substitutions come from? It was easy to recognise how this language is being generated, because when I worked as an engineer at Google I spent several years on anti-spam projects. Replacing “big data” with “enormous information” is the work of so-called spinners. Spinners are very simple tools that have been around for decades. They don’t need to generate intelligible text because their output is only meant to be read by other machines, usually, the “crawlers” that power search engines. By generating many variants of a single base article all of which link to a target page, a search engine can be fooled into thinking there is genuine widespread interest in the article across the internet, and that increases its rankings. Here’s an article about spinners by an apparently shameless web spammer who uses them.
It’s ironic that a scientific community that has generated tens of thousands of papers about “disinformation” from “social bots” is itself flooding the world with spambot generated ‘research’. Doubly ironic is the fact that the unpublished pre-print forming the basis of this article appears to have found its genesis in the investigations of a Russian software engineer working at Yandex. If you’re an academic reading this site (good job!) then you may wish to gently suggest to your colleagues that next time they are tempted to talk about misinformation, they start by addressing problems a bit closer to home.









To join in with the discussion please make a donation to The Daily Sceptic.
Profanity and abuse will be removed and may lead to a permanent ban.