
Another cluster of fake scientific papers has been discovered, this time primarily about electronic medical devices and software. A group of three researchers has published an exposé of papers in which ordinary terms like artificial intelligence and facial recognition are replaced with bizarre alternatives auto-generated from a thesaurus. This appears to be an attempt to hide plagiarism, AI-driven paper auto-generation and/or “paper mill” activity, in which companies generate forged research and sell it to (pseudo-)scientists who want to get promoted.
| GENUINE TERM | AUTO-GENERATED REPLACEMENT |
|---|---|
| Big data | Colossal information |
| Facial recognition | Facial acknowledgement |
| Artificial intelligence | Counterfeit consciousness |
| Deep neural network | Profound neural organization |
| Cloud computing | Haze figuring |
| Signal to noise | Flag commotion |
| Random value | Irregular esteem |
Often these papers originate in China, where the CCP has mandated that every single medical doctor must publish research papers to get promoted (i.e. in their non-existent spare time). If you’re new to this topic, my previous article on Photoshopped images and impossible numbers in scientific papers provides some background along with an entertaining begging letter from a Chinese doctor who got busted.
Most of the bad science covered on the Daily Sceptic is of the intellectually dishonest kind: an absurd assumption here, ignored evidence over there. Sometimes professors – like those at Imperial College London – turn out to be incapable of using computers correctly and are presenting internal data corruption in their models as ‘evidence’, a problem I wrote about in my first article for this site. While these papers are extremely serious for public trust in science, especially given the huge impact they have had, there are even worse problems lurking in the depths of the literature. The biggest is probably 100% fake papers that report on non-existent experiments, often in obscure areas of Alzheimer’s research or oncology.
Corrupt journals and their explanations
In their article (an unpublished pre-print), Cabanac, Labbé and Magazinov zoom in on a journal called “Microprocessors and microsystems“, published since 1976 by Elsevier. They document a sudden step-change in the quantity of papers being published around the end of 2019, with another massive jump at the start of 2021.
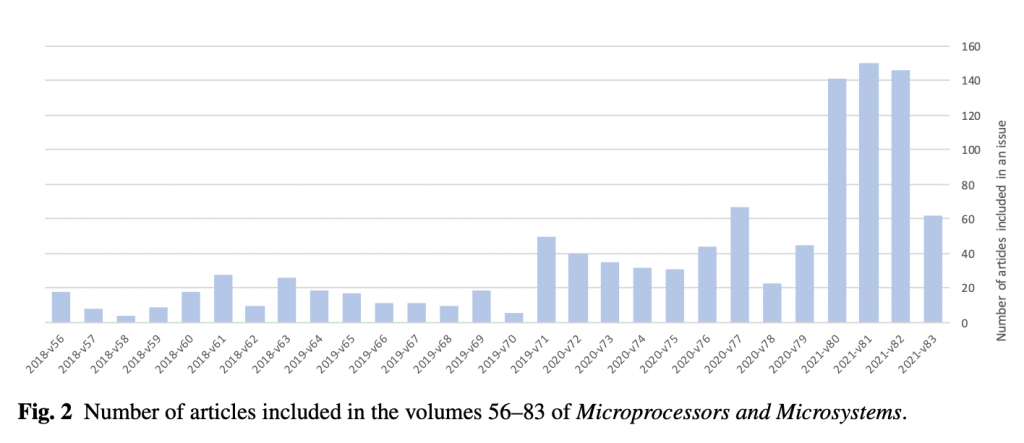
While even famous journals like Nature frequently publish intellectually dishonest nonsense, corrupt scientists seem to focus on finding especially weakly run journals and entirely subverting them. This allows them to publish papers in which the language doesn’t even make grammatical sense, let alone display intellectual rigour. Many of the papers feature not only bizarre substitutions but also plagiarised text, stolen images and of course the inevitable Photoshops.
Exactly how this process occurs is unclear because one of the most problematic aspects of the fake science phenomenon is that when asked to investigate, journals and authors invariably try to BS their way out of it. For example, last time the excuse presented by the NHS for a clearly Photoshopped image was that the patient had “worn the same shirt”, even though literally anyone could see that claim was false. And so it is again. This time the excuse we’re presented with is that:
“Unfortunately, due to a configuration error in the editorial system, the Editor in Chief or designated Handling Editor did not receive these papers for approval, as per the journal’s standard workflow. This configuration error was a temporary issue due to system migration and was corrected as soon as it was discovered“
– Microprocessors and microsystems
In other words, Elsevier is arguing that they are capable of publishing scientific papers that literally nobody has read at all, and capable of doing this for multiple entire editions of their journals without anybody noticing. Microsystems and microprocessors costs $1,893 a year for an institutional subscription, but it’s run with a less rigorous review process than this website. Is that really credible? It hardly matters; no matter what perspective you look at it from their explanation is damning. Either it’s a lie (as explanations of scientific misconduct have often been in the past), or it’s true and Elsevier are saying that they’ve been charging thousands of dollars a year for a non-existent editorial service. Remember that it’s ultimately taxpayers who fund this via government research budgets.
Medical corruption spreads to other fields
This journal is suspicious in another way: despite theoretically being about embedded micro-controllers, a quick review of the articles shows that many of them have nothing to do with this topic and in fact some of them are clearly medical papers, e.g. the last issue contains articles on watermarking algorithms for medical images. Although related to computer science, that is not related to this specific sub-field. In April what is clearly a purely medical paper was published by some nurses in China. It appears to be something related to MRI scans. I say “appears” because the paper is so garbled that it’s basically unintelligible. The final sentence of the abstract says:
“MRI is more research to enable a normal identification from pathological conditions required to provide a diagnostic reference value, to be used for functional PHV evaluation potential shows.”
This sentence doesn’t seem to contain much real meaning so it’s questionable whether it’s explainable as a bad auto-translation. The paper also passes off a circuit diagram of a simple water leak detector downloaded from a western website as an “image detection sensor using intervention after heart valve replacement”. As is often the case with investigations into scientific integrity, everything looks roughly right from a distance until you sit down and start reading carefully, at which point it all falls apart.
It’s worth stressing that this problem isn’t limited to one or two journals, nor is it exclusive to Chinese authors. A quick search on Google Scholar for “counterfeit consciousness” or “profound neural organisation” shows large numbers of results in many different journals, with Indian names also being quite prevalent.
Where do these substitutions come from? It was easy to recognise how this language is being generated, because when I worked as an engineer at Google I spent several years on anti-spam projects. Replacing “big data” with “enormous information” is the work of so-called spinners. Spinners are very simple tools that have been around for decades. They don’t need to generate intelligible text because their output is only meant to be read by other machines, usually, the “crawlers” that power search engines. By generating many variants of a single base article all of which link to a target page, a search engine can be fooled into thinking there is genuine widespread interest in the article across the internet, and that increases its rankings. Here’s an article about spinners by an apparently shameless web spammer who uses them.
It’s ironic that a scientific community that has generated tens of thousands of papers about “disinformation” from “social bots” is itself flooding the world with spambot generated ‘research’. Doubly ironic is the fact that the unpublished pre-print forming the basis of this article appears to have found its genesis in the investigations of a Russian software engineer working at Yandex. If you’re an academic reading this site (good job!) then you may wish to gently suggest to your colleagues that next time they are tempted to talk about misinformation, they start by addressing problems a bit closer to home.











To join in with the discussion please make a donation to The Daily Sceptic.
Profanity and abuse will be removed and may lead to a permanent ban.
You should try economics. They are the master of the upward sloping graph and disingenuous Y-axis settings.
Add a dose of pal review and groupthink and you have the perfect movement to push a purely political line.
This website will go down in history as being more interesting, more prescient, and more accurate than much of the bull published by “The Scientists”.
Yep – despite Toby.
Lithuania’s brutal clampdown on the jab refuseniks By Emilia Mituziene
https://www.conservativewoman.co.uk/lithuanias-brutal-clampdown-on-the-jab-refuseniks/
Stand in South Hill Park Bracknell every Sunday from 10am meet fellow anti lockdown freedom lovers, keep yourself sane, make new friends and have a laugh.
Join our Stand in the Park – Bracknell – Telegram Group
http://t.me/astandintheparkbracknell
A foretaste of what is to come in the UK unless we stop it!
Fascinating and remarkable stuff, thanks.
Wow Mark you’ve blown my mind again
Is there any way you can turn your expertise to the “studies” that underpin the lies about covid? The ones that claim to prove asymptomatic transmission for example.
Hi SweetBabyCheeses,
I’ve written several articles last year examining COVID papers under the name “Sue Denim”. You can find them in the sidebar under the modelling section. I don’t think I looked at asymptomatic transmission though.
I’ve moved on to scientific fraud in general because other contributors are doing a good job of addressing COVID, and the new wider remit of the site allowed us to look at non lockdown topics. However I can revisit specific COVID papers of there is interest and people pick some they’d like examined.
Ohhh you’re Sue Denim! Nice work. Well all I know about the Asymptomatic Papers is from this website…I think there’s been just 3-4 papers in total that have then been cited and recited and it has somehow become accepted fact that it is a source of transmission. I think a couple of the papers were from China – in particular from obscure Doctors who had published nothing before or since. Then there was a paper from Italy maybe and one from somewhere totally random like Bahrain? The most shocking thing was that the total number of asymptomatic transmissions found amongst all these studies like in the region of 6-7 instances!
“Often these papers originate in China, where the CCP has mandated that every single medical doctor must publish research papers to get promoted (i.e. in their non-existent spare time).”
Oh, those awful commies.
I don’t want to shatter your illusions, but this is the story of western academia, and has been for years. Academics effectively have quotas for advancement. Quality is irrelevant, all that matters is quantity.
Western students have been using paper milles for decades too. It is all part of the ‘I bought a degree’ syndrome of mass entrance to university. One of the early systems that academics, and students, were forced to use was TurnItIn, used to ‘detect’ plagiarism in essays.
Yes,there is some truth in that statement as Western countries are producing lots of low quality papers in order to get promotions.But China is worse.Every single paper has to get green light form a cell in the CCP.Last year I went through several Chinese studies of masks which were used by WHO and others for the mask fanatics.All thoose articles were apalling both in design and genralisations and almost parodic in the fantastic outcomes.Not a single one would have been accepted in a more prestigious journal but they were all swallowed by the maskfanatics. The grotesque article about 11 million tested in Wuhan last summer had a statement that all had given consent. Every single article from China especially about C 19 should be taken with a pinch of salt.
There’s a big difference between an essay and a published research paper. An essay will never get read by anyone else. At undergraduate level it’s highly unlikely that a student is gifted enough to have a novel thought on a subject so I imagine professors just grade the same stuff over and over anyway. They’re more looking that you can form a coherent argument using critical reasoning. If people want to cheat at this then really they’ve just cheated themselves out of learning one of the few useful things Uni could teach them!
A research paper takes years, if not decades. Faking one involves a conspiracy with your colleagues. And involves faking both real life experiments and/or results. It’s super scary because laypeople take them as the holy grail. 99% of people do not have the statistical skill to even understand anything except the intro and conclusion let alone interrogate the results. But then Policy makers persuade politicians that they need to make decisions based off these papers, and we end up in pickles like the one we’re in now!
Catching up DS – See The Illusion of Evidence Based Medicine’ -by Jon Jureidini and Leemon McHenry – a brilliant analysis of the pharma corruption of science and related journals, journalism, academia, the ex editor of the BMJ recently came out exposing this – Feyeraband’s ‘Against Method’ is playing out and t. Khun also in this vein – mixed with pure capitalism and it becomes clear how far we are from Popper and falsification principles- hardly surprising we have mass hypnosis and transhumanist loonies – The Science is a fiction.
Really excellent piece, Mike.
Thank you Sandra.