
by Sue Denim

There’s a new paper out in the Lancet called “Determining the optimal strategy for re-opening schools” by Panovska-Griffiths et al. It predicts a large wave of infections and deaths if there isn’t a big step up in contact tracing and isolation (house arrests) of PCR-positive cases. The model has been getting traction in the media, like in this segment by Sky News: “it’s just a model but clearly, that [second wave] would be disastrous”.
Unfortunately, people are being misled once again. The modelling conclusions are unsupportable.
The papers. There are two papers we’ll be looking at. One is the UK specific instantiation of the model looking at school re-openings (henceforth “the schools paper”), and the second describes the Covasim simulation program that was used to calculate the results (henceforth “the Covasim paper”). Both papers come from substantially the same team.
The model. The schools paper says the “approach is similar to that in the study by Ferguson and colleagues, which informed the implementation of lockdown measures in the U.K.”.
Covasim is a simulation structurally quite similar to the COVID-Sim program by Imperial College London we have previously looked at in part one, two and three of this series. It simulates individuals in a population as they pseudo-randomly get sick, infect contacts and sometimes die.
Indeed, Covasim is so similar to COVID-Sim that a quick perusal of the changelog shows they’ve found and fixed bugs identical to the ones discussed previously on this site. Not only does Covasim implement very similar algorithms, but it actually uses input data taken from Ferguson’s papers.
The good news is that despite algorithmic similarity the Covasim code is much higher quality than ICL’s model. There is extensive and clear documentation, the code is written in a more appropriate language and there are serious regression tests. Finally, development is funded by the Gates Foundation, not taxpayers.
A quick reality check. Most people probably won’t need to read further than this section.
The schools paper argues that the level of testing, tracing and quarantining must be much higher than it is now in order to “avert a large number of COVID-19 cases and deaths” once schools have re-opened. In this case, a “large number” means a second wave of about 2-2.5x the size of the first, ending in about 320,000 cumulative deaths. That’s the worst case they simulate which still assumes a fairly aggressive contact tracing programme.
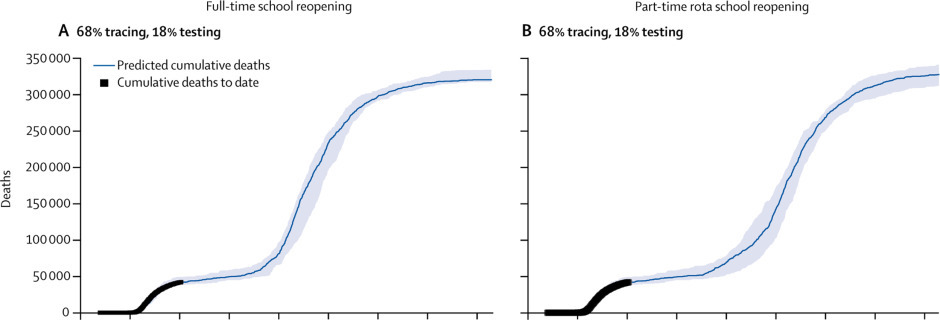
This number of predicted deaths is in the same sort of range as the ~500,000 predicted by Ferguson et al, which is no surprise given what the model does. The lower value comes from applying a reduction from some fraction of unlucky PCR-positive people being quarantined.
We already know this modelling approach doesn’t work because it failed to predict the course of the epidemic in Sweden. There is no mention in the paper of having identified any flaw in prior models that led to incorrect predictions, or even any recognition that agent-based simulations have yielded incorrect predictions before.
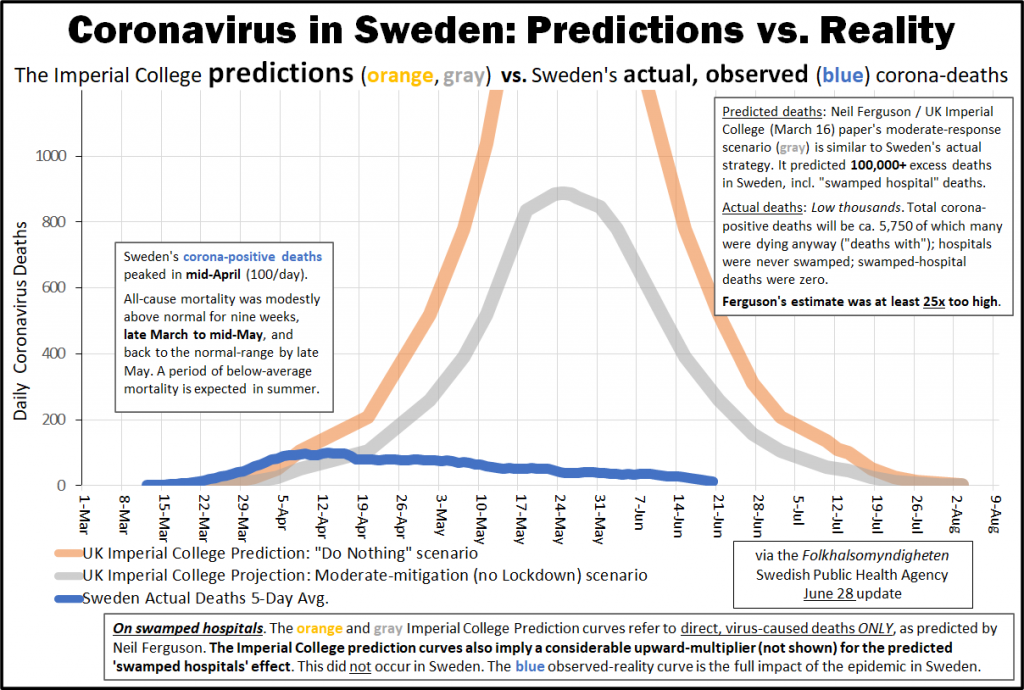
Sweden kept their schools open the entire time and saw no higher rate of infections amongst children than neighbouring Finland.
As we’ve come to expect from a group of epidemiologists, the papers do not perform this kind of cross-check against real world observed outcomes nor attempt to explain prior failures. There is no feedback loop.
Assumptions about the infectiousness of children. When looking at Ferguson’s model we focused on bugs, because assumptions are subjective and bugs are not. Even very bad assumptions are frequently hand-waved away as being mere differences of expert opinion. Bugs have the advantage that this can’t happen (regardless of how much a few academics have tried). In this case, severe bugs are pretty unlikely due to the better software engineering involved, and none jumped out while browsing the code. The model is also configured to be replicable by default, even though it has similar difficulties as COVID-Sim with reproducing its own output when run on multiple CPU cores.
So let’s turn our attention to the underlying assumptions in the hope of discovering why these models always seem to predict catastrophe.
The central claim of the study contradicts a lot of what we’re being told about COVID-19, namely that children don’t really infect adults. According to the WHO, to date, few outbreaks involving children or schools have been reported.
In fact, according to a different epidemiologist there’s not a single reported case of a teacher being infected by a pupil anywhere in the world. Schools are, in effect, a black hole for the virus – it can get in but not out:
“One thing we have learnt is that children are certainly, in the 5 to 15 brackets from school to early years, minimally involved in the epidemiology of this virus,” Professor Woolhouse, an infectious disease epidemiologist at Edinburgh University, said.
There is increasing evidence that they rarely transmit. For example, it is extremely difficult to find any instance anywhere in the world of a single example of a child transmitting to a teacher in school. There may have been one in Australia but it is incredibly rare.
If we ignore the Swedish/Finnish data match and assume children are currently waiting at home to be infected, then there is an obvious justification for predicting a wave of cases amongst children when schools re-open. But given that they neither die nor seem to infect many adults, this would not obviously lead to a huge wave of deaths.
The model disagrees because it’s programmed on the assumption those reports are all wrong and in fact children infect adults at the same rate as adults infect adults. This is justified as follows:
Data… are sparse… others have suggested that the attack rate (ie, probability that an infected individual will transmit the disease to a susceptible individual) is similar to that in adults.
Compare that to the conclusions of this meta-study from the University of Vermont, summarised with the headline “Children rarely transmit COVID-19”:
“The data are striking,” said Dr. Raszka. “The key takeaway is that children are not driving the pandemic. After six months, we have a wealth of accumulating data showing that children are less likely to become infected and seem less infectious; it is congregating adults who aren’t following safety protocols who are responsible for driving the upward curve.”
So there are contradictory perspectives on this: on one hand, the data is “sparse” and shows children being as infectious as adults; on the other, that there’s a wealth of data and children are “rarely” infectious. This is the point at which the paper’s authors could have stopped and concluded the data was too contradictory or thin for making predictions. Instead, they picked the studies that gave the most alarming outcomes and proceeded.
Given this large disparity in beliefs, I was curious about the model’s citations.
The claim that “data are sparse” is deceptive. It’s a claim written in the present tense so should have been true at the time of writing, but the citation that supposedly supports the claim is a Norwegian “rapid review” that dates from March:
We have found five documented cases of likely spread of disease from children, but as the evidence is sparse, it is too early to say if children may play an important role
This casual, four-month old remark is passed off as evidence without making its age obvious anywhere, not even in the bibliography. In fact, a different part of the cited paper undermines their case, as it says “it appears that infected children do not represent a major vector for transmission”.
Citation 10 claims the “attack rate is similar to that in adults”. A recent study put the secondary attack rate of children at 4% vs 17% for adults, or about 77% lower – far lower than this claim of identical rates. (The schools paper also ran a simulation with a 50%-of-adult attack rate, which didn’t change the results.) The citation 10 study was published in April but used data only from Shenzhen up to February. Thus, this citation, the only one given for an equal attack rate, is also long since obsolete. It’s unclear why it reached different conclusions to the others. Attack rates were calculated using statistical techniques from data provided by the Shenzhen authorities, which the study authors admit was subject to definitional and methodology changes during the collection period. This may have affected the results.
Finally, the schools paper assumes 1%-2% of all infected people die (see table 2 in the Covasim paper). This is about 10x too high compared to real observed values. The obsolete values come from the old papers of Ferguson and Verity et al at ICL. Using high IFRs seems like a common way to inflate predicted deaths. In the beginning there was an obvious and legitimate explanation for how such a mistake could happen, as only the most severe cases were reported to the authorities. By August this excuse no longer holds. This will naturally severely distort their predicted outcomes.
Usage of obsolete data seems to be a common problem in this line of work. For example, Covasim uses as a default parameter values for ‘over-dispersion’ taken from this model using data from February, at a time when most countries in their dataset had hardly any cases and in fact several countries analysed had only one case. Does such an analysis have sufficient statistical power?
Assumed malign effects of re-opening. The number of deaths the model predicts is high because it assumes lockdown is being held in place primarily by schools being closed, and thus schools re-opening would lead to a general end to lockdown. This is modelled as a 20% increase in the probability of infecting someone in the workplace. This number appears to be a guess.
Arbitrary changes in infectiousness. Covasim’s predictions are mostly tied to the value of a parameter called beta. Beta represents the base probability of someone infecting someone else, which is then scaled by various factors to account for different kinds of contacts (school, home, work, community) and different forms of social control. In other words, this is infectiousness, or what’s referred to above as the attack rate.
You might expect this value to be an inherent characteristic of the virus derived from lab work or observational studies, and wonder why it has such a meaningless name. The name is meaningless because in fact beta is a free variable. The user is meant to run a “calibration” process that searches for values of beta and other parameters automatically until the model successfully outputs the data seen so far, for whatever population you want. Phrased another way, it’s a fudge factor.
This can lead to bizarre outcomes. In standard Covasim the infectiousness of COVID is given the default value of 1.6%. Yet in the UK version of the model, infectiousness has been halved to only 0.825%. In a sample showing an earlier version of the model for the Diamond Princess cruise ship, beta has a more obvious name but another totally different value of 5%, much higher again.
This is supposedly the same virus everywhere yet its infectiousness is required to vary wildly for every situation the model is given. The model simply couldn’t output what’s actually happened so far if it didn’t have this kind of knob. Neither paper remarks on this, nor provides any biological explanation for how beta could vary so much in practice, nor ponders the implications for the general robustness of the model’s predictions.
Conclusions. This new model is structurally similar to the discredited COVID-Sim model from ICL, and also uses the same 10x too high IFRs despite much more recent data being available. Obsolete data is cherry-picked, a practice defended with equally obsolete claims that there’s not much data available to use. This yields dramatic conclusions that are then fed to the media without waiting for any sort of rigorous cross-examination (it would appear The Lancet‘s supposed peer review process and reputation are worthless).
Empirical experience from the real world implies no programme of tracing and quarantines is required to re-open schools. The virus is the same in Sweden as it is in the UK, and Swedish biology is the same as British biology. Thus claims that the UK will see huge death rates unobserved elsewhere should be treated as false until major support for the case has been built.
A final observation. Polling indicates that trust in scientists is falling.
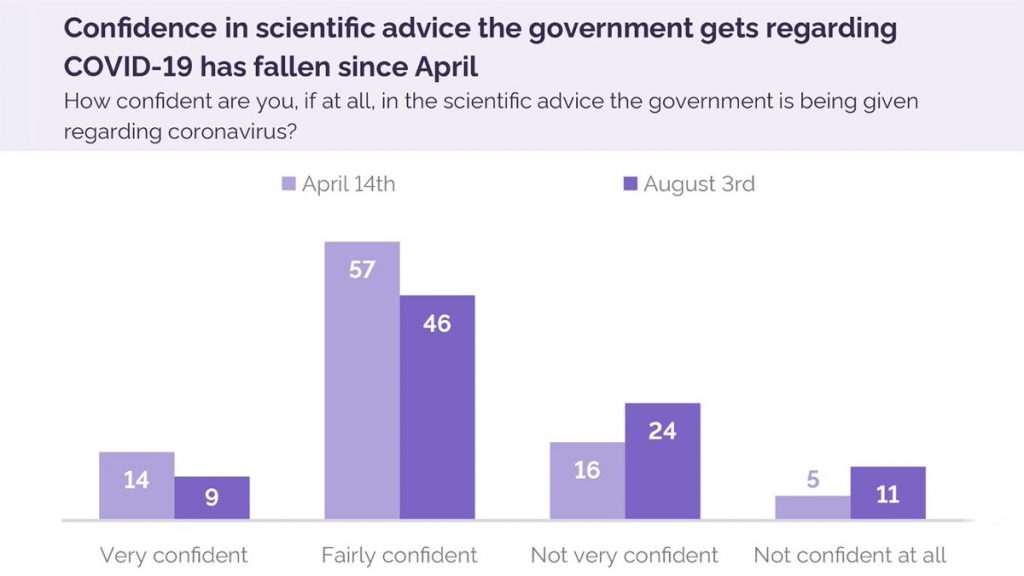
The public’s perception of “the science” is coming into line with how reliable it actually is. This trend is mostly the fault of researchers, but not entirely. Part of the blame must fall on journals like Science, Nature and The Lancet, which don’t seem to do even basic checks on papers they publish.
The core problem is motivated ideological reasoning, as demonstrated by this case where a journal rejected a paper by Gabriela Gomez et al suggesting COVID is less dangerous than predicted, because:
Given the implications for public health, it is appropriate to hold claims around the herd immunity threshold to a very high evidence bar, as these would be interpreted to justify relaxation of interventions, potentially placing people at risk.
Making this call isn’t the role of journal editors, but they don’t trust politicians or the public to do so. It’s not the only case of this type. The editors of Science also weighed up these considerations when discussing another paper that showed a low herd immunity threshold:
The relevant Science editors discussed whether it was in the public interest to publish the findings… we were concerned that forces that want to downplay the severity of the pandemic as well as the need for social distancing would seize on the results to suggest that the situation was less urgent. We decided that the benefit of providing the model to the scientific community was worthwhile.
Although that paper made it through, who knows how many other papers are being suppressed with this justification? The scientific establishment has started working backwards from their preferred social policies to whatever research supports that goal. For as long as they believe they are fighting a heroic moral battle against vaguely arrayed “forces”, trust in them will continue to fall.









To join in with the discussion please make a donation to The Daily Sceptic.
Profanity and abuse will be removed and may lead to a permanent ban.