
Some people say ‘you can prove anything with statistics’. It doesn’t seem like a very intelligent or constructive observation – but perhaps they’re onto something.
In a paper published in Proceedings of the National Academy of Sciences, Nate Breznau and colleagues outline an intriguing study where teams of social scientists tested the same hypothesis using the same data, but got radically different results. Here’s how it worked.
Seventy-three teams of social scientists were invited to take part. The aim of the study was to gauge the extent to which idiosyncratic decisions by researchers influence the results of their statistical analyses. All teams were given the same data and asked to test the same hypothesis, namely “that greater immigration reduces support for social policies among the public”.
After analysing the data, each team submitted their results, along with details of the models they had run. The researchers behind the study examined all the models and identified 107 different analytical decisions. These comprised things like which variables were included, which type of model was used and whether any data were excluded.
They then performed their own analysis to see whether variation in teams’ results could be explained by the analytical decisions they had made. Did teams that included the same variables get similar results? Did teams that used the same type of models get similar results? Etcetera.
First things first, though. How similar were teams’ results overall? Did most of them find support for the hypothesis “that greater immigration reduces support for social policies among the public”?
The answer is shown in the chart below. Each coloured dash represents a different statistical estimate submitted by one of the teams. (There are more than 73 because some teams submitted more than one.) The horizontal axis ranks the estimates from smallest to largest. The vertical axis indicates their exact size and whether they are positive or negative.
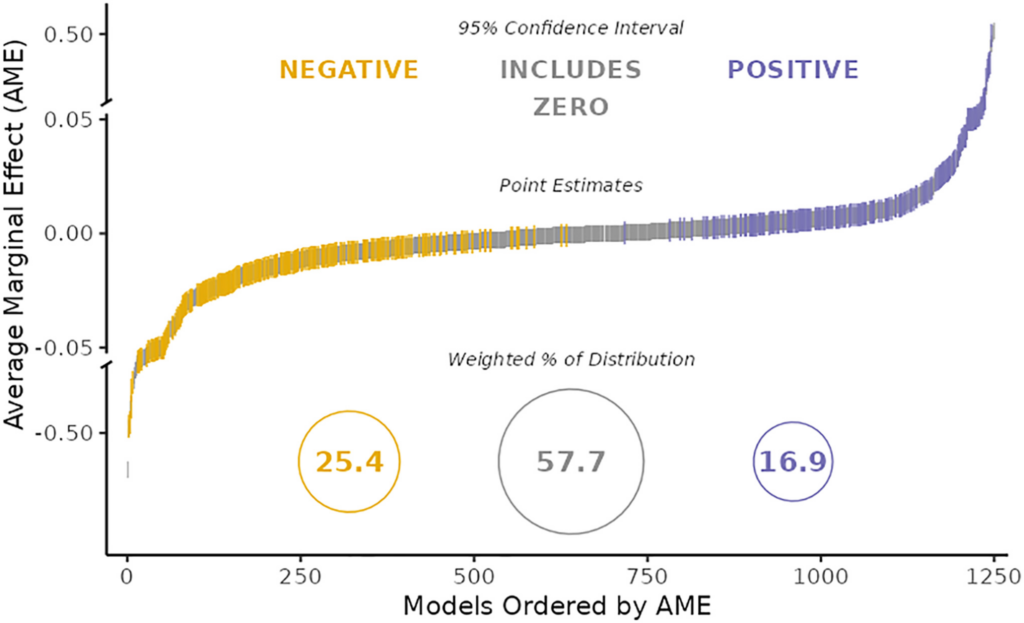
As you can see, teams’ results were highly dissimilar. Some submitted moderately large negative effects (shown in yellow); some submitted null results (shown in grey); and some submitted moderately large positive effects (shown in purple).
In other words, there was absolutely no consensus as to whether greater immigration reduces support for social policies. Some teams found that it does; others found that it doesn’t; and still others reported mixed results. This was despite the fact that all teams had exactly the same data.
Were Breznau and colleagues able to explain variation in teams’ results with reference to the analytical decisions they made?
The answer is shown in the chart below. Each of the four bars represents a different way of measuring the variation in teams’ results. Colours represent different explanatory factors – analytical decisions are shown in green. (Breznau and colleagues also checked to see whether things like researcher characteristics mattered.)
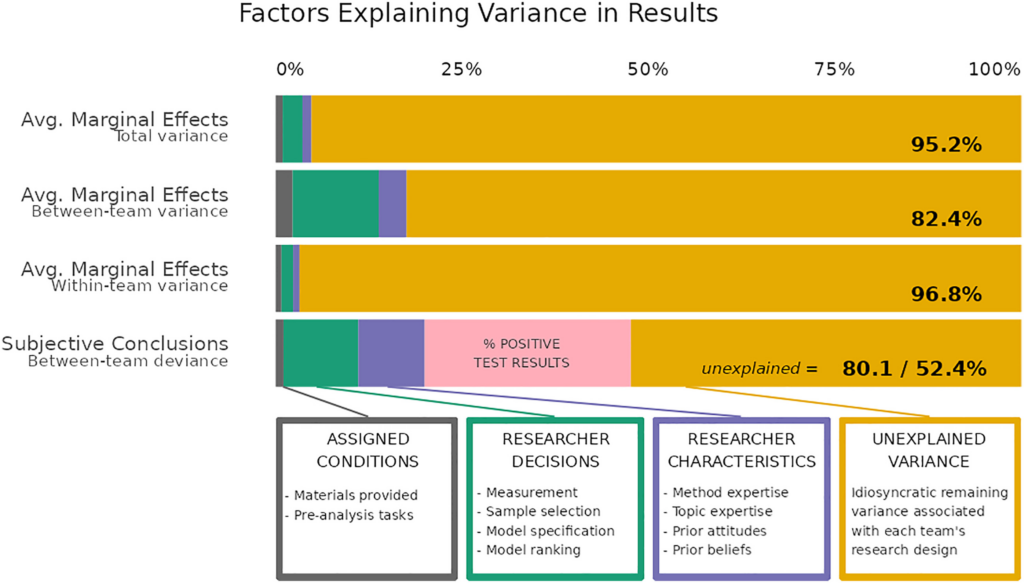
As you can see, the vast majority of variation in teams’ results went unexplained. When you think about it, this is a remarkable finding. Social scientists tested the same hypothesis using the same data, and got radically different results. Yet the analytical decisions they made don’t seem to explain why they got such different results.
What else could explain it? Here’s a quote from the paper:
Researchers must make analytical decisions so minute that they often do not even register as decisions. Instead, they go unnoticed as nondeliberate actions following ostensibly standard operating procedures. Our study shows that, when taken as a whole, these hundreds of decisions combine to be far from trivial.
Social scientists have plenty of reasons to feel humble. Breznau and colleagues just gave them one more.
Stop Press: Breznau and colleagues’ paper has been criticised for overstating the variation in teams’ results. Maya Mathur and colleagues point out that 90% of the standardised effect sizes were between –0.037 and 0.037, suggesting a consensus of little or no effect.









To join in with the discussion please make a donation to The Daily Sceptic.
Profanity and abuse will be removed and may lead to a permanent ban.