
A U.S. science magazine produced by Massachusetts General Hospital has published an article on the “trash island” created by fraudulent computer-generated papers in the scientific literature (emphasis is mine):
Bad science can do lasting damage … [some studies] go beyond bad data and are wholly fraudulent from their inception. A curious subset of these are scientific papers that are generated by computer programs. Custom algorithms can contribute sections or even spin up whole papers by splicing together likely-sounding phrases or linguistically twisting already-published results. Such papers get printed, even by reputable publishers, and while many of these papers have been retracted, some are still being cited in the scientific literature years after their retraction.
Stephen Ornes, Proto Magazine
The problem of academics and medical staff successfully publishing peer-reviewed gibberish is one we’ve written about previously at the Daily Sceptic. Although it’s good that the issue is being surfaced in pop-science magazines, the report itself adds little new information, being based entirely on the work of the tiny handful of volunteer bloggers and researchers who investigate fake papers. Instead it’s worth reading in full to study the responses by science insiders. It appears that the seeds are being sown for a destruction of confidence in science that could be even greater than the fallout from Covid.
To understand what might happen we need to briefly review the latest breakthroughs in the field of artificial intelligence.
Generative transformer models
20th century science fiction usually depicts artificial intelligence (AI) as cold, analytical calculating machines driven by pure logic. Twenty-first century AI is shaping up quite differently. The invention of generative transformer models has opened the era of creative, imaginative AI that can invent original material difficult to distinguish from that created by humans. A fun demonstration posted in recent days is the output of the DALL-E 2 model when asked to draw pictures of Kermit the frog.

You can find many more examples of DALL-E 2’s output by searching Twitter or looking at the official website.
Whilst DALL-E 2 generates images given a short prompt, the more famous GPT-3 model generates text. Here’s what it generates given the writing prompt “Here’s a standup comedy show by Peter Thiel, Elon Musk and Larry Page about how much it sucks to run a company.”
Larry: I think I’m going to do a reddit AMA.
GPT-3
Peter: I think that’s a terrible idea. You know how brutal they are on Reddit, right?
Larry: I do.
Peter: It’s the internet. That’s like stepping into a bear cage.
Larry: I’m not scared of bears.
Peter: Yeah, but think about it. When you go in there, they’re all going to be…
Larry: I don’t care if I get eaten by bears. You’re always telling me I should get out more and socialize.
Peter: Socialising on the internet is like if you walked into a bar and everyone there had only read about alcohol, but never actually tried it. You’ll be torn to shreds.
Larry: I don’t understand how the internet could possibly be worse than some of the stuff that’s happening in the news these days.
Peter: The news is funny because you know it’s fake, right? It’s not actually that bad. But if you go on Reddit and tell people that one plus one is two, they’re going to Photoshop your face onto a frog and put you in a Hitler moustache and have you firing rockets into space.
Given any starting point, these models will generate an unlimited number of random but plausible completions based on complex statistical models fitted to everything found on the internet. The difficulty this poses for academic processes is immediate and profound. Scientific writing is an extremely specific style, and some fields (like biology) produce many extremely similar sounding papers. This presents an absolutely ideal scenario for generative models, which as a consequence will happily start producing fake scientific papers without that even being requested:
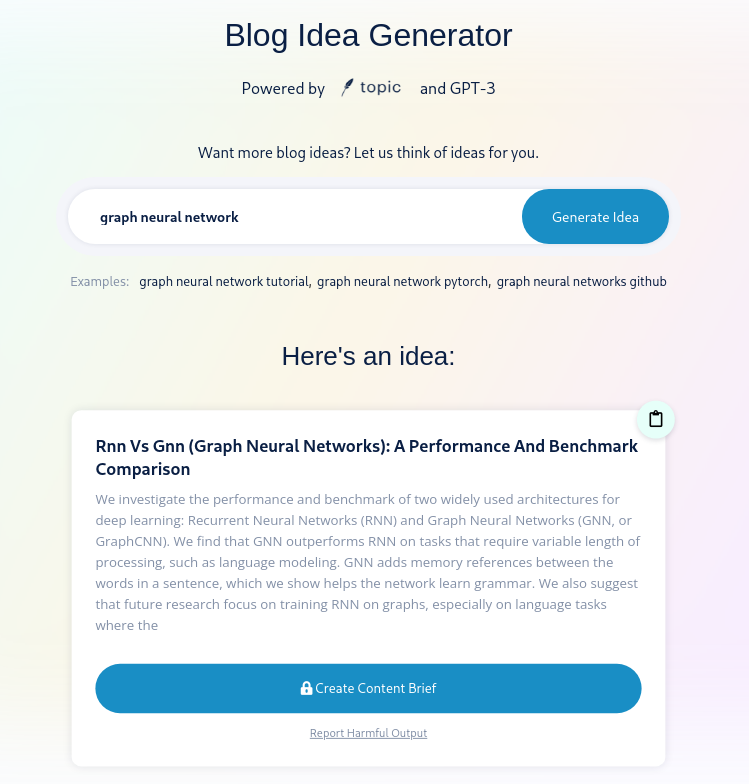
The person above wanted blog post ideas and got a complete fake abstract for an AI related paper, complete with claims about non-existent experiments and randomly generated suggestions for future work.
What if you do request a paper? A researcher who studies the applicability of AI to cardiac imaging got access to the older GPT-2 model and explicitly asked it to write fake medical papers. Here’s his first result, in which the title was written by him and everything else was written by the AI, including the fake registration data at the end. It apparently contains mistakes, but only mistakes of the type an expert paying close attention would notice:

If you’re getting worried about pending mass unemployment in the creative arts, try reading Gary Marcus to get a sceptical view and see examples of where these AIs break down (and a rebuttal by Scott Alexander). The summary is that they struggle with all forms of logical reasoning and structure – ironically so, given that they’re computers. It must also be noted that the firms behind these models are seriously limiting access to them, with the excuse that they tend to generate images displeasing to woke ideology (e.g. pictures of white males when prompted with “builders”). They’re also imposing many rules on what examples people are allowed to reshare, and preventing sceptics from testing them deeply. Gary Marcus can’t get direct access to these models and has to go via friends, a problem almost certainly caused by his reliably sceptical stance. We should be wary of getting too excited about these new capabilities whilst we can rely only on claims by the developers and their friends.
The problem
Getting fake papers published is just far too easy, even with crude tools that pre-date recent AI breakthroughs. Over and over it turns out that, in many cases, nobody can actually have read articles being presented as having been carefully peer-reviewed by university professors. Examples covered on this site in the past few years include:
- Publisher retracts 24 papers for being “nonsensical”
- 436 randomly generated peer-reviewed papers published by Springer Nature
- Fake Science: the misinformation pandemic in scientific journals
The problem isn’t restricted to fully computer-generated ‘research’. Papers written by humans can easily contain erroneous statements or absurd methodologies that somehow don’t get detected, like the Covid modelling paper we previously studied here in which the very first sentence was a factually false claim about public data.
The fake papers in the three articles above probably weren’t created with modern AI, as their sudden topic switches and ungrammatical paragraphs are of far lower quality than what is now possible. Even so, the fact that not only one or two articles but entire editions of entire journals can be filled with auto-generated text and it’s outsiders who notice, suggests a disaster may be looming for the literature. In an environment where millions of people are paid to get papers published, peer review goes AWOL surprisingly often, research fraud is hardly ever penalised and the truth of those papers is only rarely checked, generative models represent a shortcut to the top that may prove irresistible.
There’s some evidence this may be happening already. In their paper “Tortured phrases” (Cabanac, Labbé & Magazinov 2021) the authors run a program designed to measure the likelihood that text is generated by an older generation of AI, and discover many journals in which abstracts are given a high probability of being machine generated. On manually spot-checking the results they find a large quantity of nonsensical text, irrelevant images and other signs of industrial scale science faking. Their paper is well written and thorough, so one might think it would have made waves in academia. But you’d be wrong – their paper has been cited a grand total of four times. A different investigation by Anna Abalkina into a commercial research faking firm concluded (emphasis mine):
The study allowed us to identify at least 434 papers that are potentially linked to the paper mill … coauthored by scholars associated with at least 39 countries and submitted both to predatory and reputable journals. The value of coauthorship slots offered by “International Publisher” LLC in 2019-2021 is estimated at $6.5 million. Since the study analysed a particular paper mill, it is likely that the number of papers with forged authorship is much higher.
Anna Abalkina
Once again, science appears to be uninterested in the integrity of its own processes. Abalkina’s paper is languishing with no citations at all.
Possible solutions
Solving this problem is not very complicated, in principle. Generative transformer models can make content that looks like something a scientist could have written, but can’t actually do research work. They’re just very fancy auto-complete.
In the private sector the possibility of fraud is taken for granted and many systems have evolved to find and prevent it, most obviously the audited set of company accounts. Many other mechanisms exist, which is why Elizabeth Holmes went to prison for exaggerating her research achievements (she defrauded investors). In contrast, scientific papers are usually taken at face value by the research community. While peer reviewers (might) read the paper and try to determine if it works on its own terms, nobody audits labs to ensure that work claiming to be done actually was done. The closest thing to a lab audit is the replication study, but a failure to replicate can be caused by many things and at any rate replication studies aren’t well funded. This is why some journal editors estimate the number of fraudulent studies they publish ranges from 20% to half.
It seems scientific journals face a choice. They can either evolve into full blown audit organisations that take direct responsibility for the accuracy and quality of the claims they publish. (This would mean publishing fewer papers and charging more money, but the results would be more useful.) Or they can continue pushing this work onto volunteer peer reviewers who get nothing for their efforts, frequently burn out as a consequence, and don’t have the ability to do meaningful audits anyway.
At the moment journals are trying to pursue a muddied middle path, in which they are adding various kinds of automated peer reviews to their editing pipeline. Proto Magazine bravely tries to give journals credit for effort while being vague, but the nature of what the journals are doing is often vague:
Prominent journals are beginning to take the problem more seriously and have implemented better screening processes for submissions – in part because of Cabanac’s work. “We must all be aware of the problem,” says Cabanac, “and stay vigilant.”
Proto Magazine
“Better screening processes” means things like running papers through third party AI detector programs, a very time limited tactic given the astounding progress in generative AI.
So journals are for now content to let the problem fester. Trying to set up some kind of comic-book-esque bot battle lets them claim to be fighting fraud without actually spending any significant money or changing their business models, but it’s an approach doomed to failure. They only have a small window of time to figure out an alternative: while the best models like GPT-3 are currently restricted and monitored by the firms that created them, more accessible alternatives are already springing up.
Can governments impose quality rules directly? The U.K. Research Excellence Framework is an illustrative example of the difficulties of this approach. It’s an occasional exercise in bulk peer review that replaced the older Research Assessment Framework. The new framework was developed partly to try to incorporate research impact into the assessment, and claims to measure research quality in a scalable manner. But it includes among its goals “promoting equality and diversity”, which – regardless of whether you support it or not – isn’t a direct measurement of research quality. The questionable accuracy of this framework can be seen by the fact that the top ranked university by quality in 2021 was none other than Imperial College London, a university that is now notorious for producing floods of junk quality epidemiology without even the slightest concern for scientific basics, like solving equations correctly, or admitting when your predictions are wrong. It appears that academia is unable to measure its own quality in a way outsiders would agree with.
Conclusions
The problem of fake research is under-studied. Given the observable output of “paper mills” it seems certain that only a tiny fraction of the fake papers being sold are detected. The problem seems to be on the rise, but that could also be a false impression created by greater scrutiny. One thing we can say for sure is that the cost of generating ‘DeepFaked’ research will soon be rapidly falling.
Although the most obvious sector to be impacted will be the arts, my personal view is that AI will ultimately be a boon for creative entertainment of all kinds. For science, things look much darker. A community that already struggles to detect and exclude rule-breakers is now suffering the consequences in terms of public trust. But the impact of fake papers on internal trust could be even worse. What do you do if you want to build upon an enticing-sounding claim in a paper, but can’t be sure the paper was even written by a human?













To join in with the discussion please make a donation to The Daily Sceptic.
Profanity and abuse will be removed and may lead to a permanent ban.
Given what we’ve been forced to witness these last few years, I’m not sure human scientists are that much better. Highly recommend this week’s Dark Horse podcast on the topic of whether we are currently in a Dark Age of science caused by bad incentives including jobs, status, and of course money. There is now an incentive for experiments to be as expensive and complex as possible in order to secure the highest funding. And the ‘peer review’ process which we’re constantly told is the Gold Standard and that were must ignore any research that hasn’t undergone it, well it’s only as good as the peers, who have the same bad incentives.
Universities have got a lot to answer for.
It’s rather lonely btl these days
Not half CG.
I am disappointed that so few of us have revealed ourselves as paying subscribers – for the sake of £5 per month or 16 pence per day.
For those sites I use regularly I believe I have a responsibility to pay for their work. These sites don’t run themselves. Some websites I use but infrequently and as much as I would like to contribute I cannot justify the expenditure. At the moment I must be around the 20-25 pounds per week on alternative media. And a limited income.
If people who were using DS regularly cannot contribute as little as 16 pence per day we are in sad times indeed. Some people were spending more time on here than me. And there are quite a few posters who I miss, so if you are reading this please set up a subscription and don’t let this site disappear. It cannot run on fresh air.
Amazing how people dissolve when money is requested. Suddenly, when the hat goes around, they weren’t really watching or enjoying the street performer, they were just passing…
Let’s give them the benefit of the doubt. Maybe they contributed and haven’t yet figured out they need to log out and back in again…. Maybe the DS Web Developer is working on that bug.
Proper journalism is so important. Happy to pay!
At least we’ve lost the (possible) trolls! Now we can just argue with ourselves and always be right! Yay for confirmation bias!
I do worry that I might become a failure to myself if I fall for confirmation bias.
There’s always a silver lining!
Agreed. I particularly miss the comments from RedHotScot
I’m working on an AI commenter.
I agree with your comment and yes am mayonnaise request.
I like what you did there