
Out of the Darkness and Into the Murk
This article takes a look at the quality of the software behind Professor Neil Ferguson of Imperial College London’s infamous “Report 9“. My colleague Derek Winton has already analysed the software methods; I will consider the quality of the development process.
Firstly, you’ll want to inspect my bona fides. I have an MSc in engineering and a lifetime in engineering and IT, most of which has been spent in software and systems testing and is now mainly in data architecture. I have worked as a freelance consultant in about 40 companies including banks, manufacturers and the ONS. The engineer in me really doesn’t like sloppiness or amateurism in software.
We’re going to look at the code that can be found here. This is a public repository containing all the code needed to re-run Prof. Ferguson’s notorious simulations – feel free to download it all and try it yourself. The code will build and run on Windows or Ubuntu Linux and may run on other POSIX-compliant platforms. Endless fun for all the family.
The repository is hosted (stored and managed) in GitHub, which is a widely-used professional tool, probably the world’s most widely-used tool for this purpose. The code and supporting documentation exist in multiple versions so that a full history of development is preserved. The runnable code is built directly from this repository so a very tight control is exercised over the delivered program. So far, so very good industrial practice. The code itself has been investigated several times, so I’ll ignore that and demonstrate some interesting aspects of its metadata.
Firstly, the repository was created on March 22nd 2020, one day before the first – disastrous – lockdown in England was applied. There was a considerable amount of development activity from mid-April until mid-July (see below) and then a decreasing level of activity until by the end of December 2020 development had practically ceased. In February 2021, however, work restarted and peaked in April, falling away again quite quickly. Since then it has been almost entirely quiescent and appears to have been totally silent since July 2021. The repository was substantially complete by mid-June 2020 and almost all activity since then has been in editing existing code.
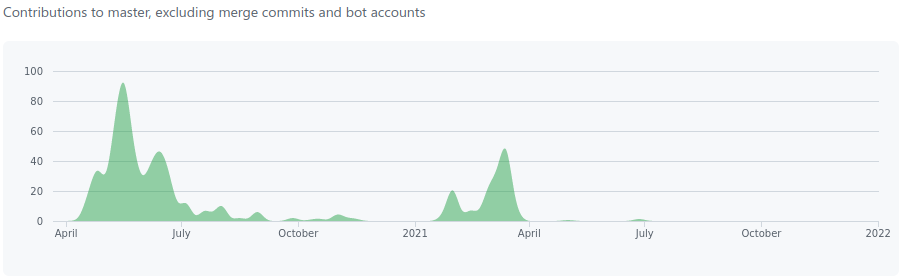
As “Report 9” was published on March 16th 2020, and the criticism of it started almost immediately, it’s very tempting to suggest that the initial period of activity matches the panic to generate something presentable enough to show to the public to support the Government’s initial lockdown. The second campaign of work may be revisions to tune the code to better match the effects of the vaccination programme.
Twenty-two people have contributed to the codebase, including the aforementioned Derek Winton. The lead developer seems to be Wes Hinsley, who is a researcher at ICL. He has an MSc in Computer Engineering and a doctorate in Computing and Earth Sciences, so would appear to be well-qualified to manage the development of something such as this.
This repository is unusual in that it appears to contain every aspect of the software development life cycle – designs and specifications (such as they are), code, tests, test results and defect reports. This is symptomatic of a casual approach to software development management and is often seen in small companies or in unofficial projects in large companies.
However, it does mean that we can gain a good understanding of the real state of the project, which is that it is not as good as I would have hoped it would be for such an influential system. We can read a lot from the “issues” that have been recorded in GitHub.
Issues are things such as test defects, new features, comments and pretty much anything else that people want to be recorded. They are written by engineers for other engineers, so generally are honest and contain good information: these appear to be very much of that ilk. Engineers usually cannot lie; that is why we are rarely ever allowed to meet potential customers before any sale happens. We can trust these comments.
The first issue was added on April 1st 2020 and the last of the 487 so far (two have been deleted) was added on May 6th 2021. Out of the 485 remaining, only two have been labelled as “bugs”, i.e., code faults, which is an unusually low number for this size of a codebase. However, only two are labelled as “enhancements” and in fact a total of 473 (98%) have no label at all, making any analysis practically impossible. This is not good practice.
Only one issue is labelled as “documentation” as there is a branch (folder) specifically for system documentation. The provided documentation looks to be reasonably well laid out but is all marked as WIP – Work in Progress. This means that there is no signed-off design for the software that has been central to the rapid shutdown and slow destruction of our society.
At the time of writing – May 2022 – there are still 33 issues outstanding. They have been open for months and there is no sign that any of these is being worked on. The presence of open issues is not in itself a problem. Most software is deployed with known issues, but these are always reported in the software release notes, along with descriptions of the appropriate mitigations. There do not appear to be any release notes for any version of this software.
One encouraging aspect of this repository is the presence of branches containing tests, as software is frequently built and launched without adequate testing. However, these are what we in the trade call ‘unit’ tests – used by developers to check their own work as it is written, compiled and built. There are no functional tests, and no high-level test plans nor any test strategy. There is no way for a disinterested tester to make any adequate assessment of the quality of this software. This is extremely poor practice.
This lack of testing resource is understandable when we realise that what we have in this GitHub is not the code that was used to produce Neil Ferguson’s “Report 9”: it is a reduced, reorganised and sanitised version of it. It appears that the state of the original 13,000-plus line monolith was so embarrassing that Ferguson’s financial backer, the Bill and Melinda Gates Foundation, rushed to save face by funding this GitHub (owned by Microsoft) and providing the expert resource necessary to carry out the conversion to something that at least looks like and performs like modern industrial software.
One side-effect of this conversion, though, has been the admission and indeed the highlighting, of a major problem that plagued the original system and made it so unstable as to be unsafe to use, although it was often denied.
We Knew It Was Wrong, Now We Know Why
One of the major controversies that almost immediately surrounded Neil Ferguson’s modelling software once the sanitised version of the code was released to the public gaze via GitHub was that it didn’t always produce the same results given the same inputs. In IT-speak, the code was said to be non-deterministic when it should have been deterministic. This was widely bruited as an example of poor code quality, and used as a reason why the simulations that resulted could not be trusted.
The Ferguson team replied with statements that the code was not intended to be deterministic, it was stochastic and was expected to produce different results every time.
Rather bizarrely, both sides of the argument were correct. The comments recorded as issues in GitHub explain why.
Before we go any further I need to explain a couple of computing terms – deterministic and stochastic.
Deterministic software will always provide the same outputs given the same inputs. This is what most people understand software to do – just provide a way of automating repetitive processes.
Stochastic software is used for statistical modelling and is designed to run many times, looping round with gradually changing parameters to calculate the evolution of a disease, or a population, or radioactive decay, or some other progressive process. This type of program is designed with randomised variables, either programmed at the start (exogenous) or altered on the fly by the results of actual runs (endogenous) and is intended to be run many times so that the results of many runs can be averaged after outlying results have been removed. Although detailed results will differ, all runs should provide results within a particular envelope that will be increasingly better defined as research progresses.
This is a well-known modelling technique, sometimes known as Monte Carlo simulation – I’ve programmed it myself many years ago, and have tested similar systems within ONS. Stochastic simulation can be very powerful, but the nature of the iterative process can compound small errors greatly, so it is difficult to get right. Testing this kind of program is a specialist matter, as outputs cannot be predicted beforehand.
To explain the initial problem fully: people who downloaded the code from GitHub and ran it more than once would find that the outputs from the simulation runs would be different every time, sometimes hugely so, with no apparent reason. Numbers of infections and deaths calculated could be different depending on the type of computer, operating system, amount of RAM, or even the time of day.
This led to a lot of immediate criticism that the software was non-deterministic. As mentioned above, the Ferguson team retorted that it was meant to be stochastic, not deterministic, and in the GitHub repository we find the following supporting notes (screenshot below). The third one is important.
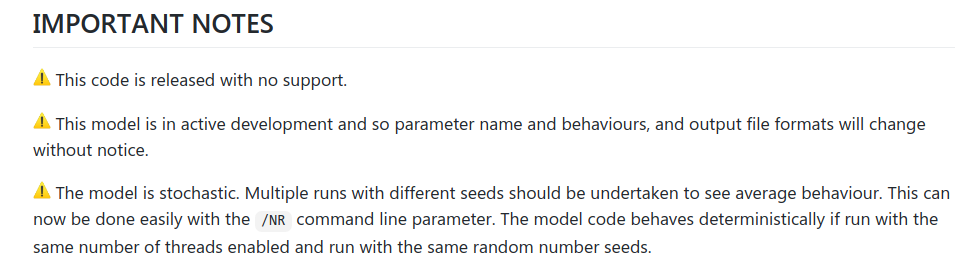
So it’s meant to be stochastic, not deterministic. That would be as expected for statistical modelling software. The problem is that, when we look at what the honest, upstanding engineers have written in their notes to themselves (screenshot below), we find this noted as Issue 161:
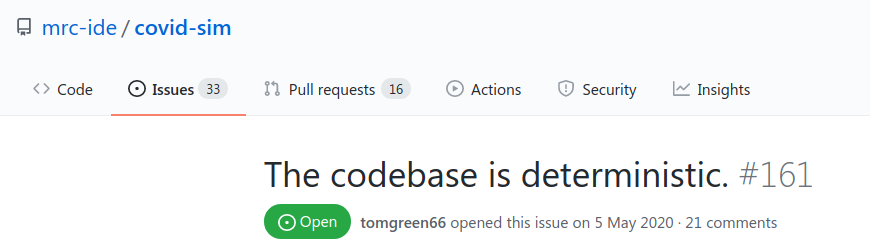
Of the 487 issues originally opened against this project, only one is considered important enough to be pinned to the top of the list. As you can see, it directly contradicts the assertions from the Ferguson team. That’s why engineers aren’t allowed to talk to customers or the public.
Reading the detail in Issue 161 reveals why the system is simultaneously deterministic and stochastic – a sort of Schrödinger’s model of mass destruction.
It turns out that the software essentially comprises two distinct parts: there is a setup (deterministic) stage that sets all of the exogenous variables and initialises data sets; and the second (stochastic) part that actually performs the projection runs and is the main point of the system.
The setup stage is intended to be – and in fact must be from a functional point of view – entirely deterministic. For the stochastic runs to be properly comparable, their initial exogenous variables must all be exactly the same every time the stochastic stage is invoked. Unfortunately, Issue 161 records that this was not the case, and explains why not.
It’s a bit technical, but it involves what we in the trade call ‘race conditions’. These can occur when several processes are run simultaneously by multi-threaded code and ‘race’ to their conclusions. Used properly, this technique can make programs run very quickly and efficiently by utilising all processor cores. Used wrongly, it can lead to unstable programs, and this is what has happened in this case. In the trade we would say that this software is not ‘thread safe’.
Race conditions happen when processes do not always take a consistently predicted amount of time to complete and terminate in unexpected sequences. There are many reasons why this may happen. This can mean that a new process can start before all of its own expected initial conditions are set correctly. In turn this makes the performance of the new process unpredictable, and this unpredictability can compound over perhaps many thousands of processes that will run before a program finishes. Where undetected race conditions occur, there may be many thousands of possible results, all apparently correct.
They may be due to differences in processor types or local libraries. There are many possible causes. Whatever the cause in this instance, every time this code was run before May 6th 2020 (and probably up to about 17th May 2020 when Issue 272 was opened and the code simplified) the result was unpredictable. That was why the results differed depending on where it was run and by whom, not because of its stochastic nature.
In itself, this problem is very bad and is the result of poor programming practice. It is now fixed so shouldn’t happen again. But, as we shall see, we cannot depend even on this new code for reliable outputs.
Where It All Came From and Why It Doesn’t Work
I have had the opportunity to work with a multitude of very capable professionals over the quarter century or so that I have been a freelance consultant, in many different spheres. Very capable in their own specialism, that is; when it came to writing code, they were nearly all disasters. Coding well is much harder than it seems. Despite what many people think, the development of software for high-consequence applications is best left not to subject experts, but to professional software developers.
I have no information as to the genesis of Professor Ferguson’s modelling code, but I’m willing to bet it followed a route similar to one that I have seen many times. Remember that this codebase first saw silicon many years ago, so came from a simpler, more innocent age.
- Clever Cookie (CC) has a difficult problem to solve
- CC has a new computer and a little bit of programming knowledge
- CC writes a program (eventually) to successfully solve a particular problem
- CC finds another problem similar to, but not identical to, the previous one
- CC hacks the existing code to cope with the new conditions
- CC modifies the program (eventually) to successfully solve the new problem
- GOTO 4
And so the cycle continues and the code grows over time. It may never stop growing until the CC retires or dies. Once either of those events happens, the code will probably also be retired, never to run again, because nobody else will understand it. Pet projects are very often matters of jealous secrecy and it is possible that no-one has ever even seen it run. There will be no documentation, no user guides, no designs, probably not even anything to say what it’s meant to do. There may be some internal comments in the code but they will no longer be reliable as they will have been written for an earlier iteration. There are almost certainly no earlier local versions of the code and it may only exist on a single computer. Worse than that, it may exist in several places, all subtly different in unknown ways. There would be no test reports to verify the quality of any of its manifestations and check for regression errors.
If Professor Ferguson had been suddenly removed from Imperial College in January 2020, I am confident that the situation described above would have obtained. The reason why I am confident about this is that none of the collateral that should accompany any development project has been lodged in the GitHub repository. Nothing at all. No designs, no functional or technical descriptions, no test strategy, test plans, test results, defect records or rectification reports; no release notes.
To all intents and purposes, there is no apparent meaningful design documentation and I know from talking with one of the contributors to the project that this is indeed the case. Despite this, Wes Hinsley and his team have managed to convert the original code (still never seen in public) into something that looks and behaves like industrial-quality bespoke software. How could have they managed to do this?
Well, they did have the undoubted advantage of easy access to the originator, ‘designer’ and developer of the software himself, Professor Neil Ferguson. In fact, given the rapid pace of the initial development, I suspect he was on hand pretty much all of the time. However, development would not have followed anything vaguely recognisable as sound industrial practice. How could it, with no design or test documentation?
I have been in this position several times, when clients have asked me to test software that replaces an existing system. On asking for the functional specifications, I am usually told that they don’t exist but “the developers have used the existing system, just check the outputs against that”. At that point I ask for the test reports for the existing system. When told that they don’t exist, I explain that there is no point in using a gauge of unknown quality and the conversation ends, sometimes in an embarrassed silence. I then have to spend a lot of time working out what the developers thought they were doing and generating specifications that can be agreed and tested.
What follows is only my surmise, but it’s one based on years of experience. I think that Wes was asked to help rescue Neil’s reputation in order to justify Boris’s capitulation to Neil’s apocalyptic prognostications. Neil couldn’t produce any designs so he and Wes (and the team) built some software using 21st century methods that would replicate the software that had produced the “Report 9” outputs.
As the remarkably swift development progressed, constant checks would be made against the original system, either comparing outputs against previous results or based on concurrent running with similar input parameters. The main part of the development appears to have been largely complete by the third week of June 2020.
The reason that I describe this as remarkably swift is that it is a complicated system with many inputs and variables, and for the first six weeks or so it would not have been at all possible to test it with any confidence at all in its outputs. In fact, for probably the first two months or so the outputs would probably have have been so variable as to be entirely meaningless.
Remember that it wasn’t until May 5th 2020 – six weeks after this conversion project started – that it was realised that the first (setup) part of the code didn’t work correctly at all so the second (iterative) part simply could not be relied on. Rectifying the first part would at least allow that part to be reliably tested, and although there is no evidence of this having actually happened, we can probably have some confidence that the setup routine produced reasonably consistent sets of exogenous variables from about May 12th 2020 onwards.
A stable setup routine would at least mean that the stochastic part of the software would start from the same point every time and its outputs should have been more consistent. Consistency across multiple runs, though, is no guarantee of quality in itself and the only external gauge would likely have been Professor Ferguson’s own estimations of their accuracy.
However, his own estimations will have been conditioned by his long experience with the original code and we cannot have much confidence in that, especially given its published outputs in every national or international emergency since Britain’s foot and mouth outbreak in 2001. These were nearly always wrong by one or two orders of magnitude (factors of 10 to 100 times). If the new system produced much the same outputs as the old system, it was also almost certainly wrong but we will probably never know, because that original code is still secret.
The IT industry gets away with a lack of rigour that would kill almost any other industry while at the same time often exerting influence far beyond its worth. This is because most people do not understand its voodoo and will simply believe the summations of plausible practitioners in preference to questioning them and perhaps appearing ignorant. Politicians do not enjoy appearing ignorant, however ignorant they may be.
In the next section we are going to go into some detail about the deficiencies of amateur code development and the difficulties of testing stochastic software. It will explain why clever people nearly always write bad software and why testing stochastic software is so hard to do that very few people do it properly. It’s a bit geeky so if you are not a real nerd, please feel free to skip on to the next section.
Gentlemen and Players
You’ll remember from above that our Clever Cookie (CC) had decided to automate some tricky problems by writing some clever code, using this procedure.
- CC has a difficult problem to solve
- CC has a new computer and a little bit of programming knowledge
- CC writes a program (eventually) to successfully solve a particular problem
- CC finds another problem similar to, but not identical to, the previous one
- CC hacks the existing code to cope with the new conditions
- CC modifies the program (eventually) to successfully solve the new problem
- GOTO 4
The very first code may well have been written at the kitchen table – it often is – and brought into work as a semi-complete prototype. More time is spent on it and eventually something that everyone agrees is useful is produced. The dominant development process is trial and error – lots of both – but something will run and produce an output.
For the first project there may well be some checking of the outputs against expected values and, as long as these match often enough and closely enough, the code will be pronounced a success and placed into production use.
When the second project comes along, the code will be hacked (an honourable term amongst developers) to serve its new purposes. The same trial and error will eventually yield a working system and it will be placed into production for the second purpose. It will also probably remain in production for its original purpose as well.
Now, during the development of the second project it is possible, although unlikely, that the outputs relevant to the first project are maintained. This would be done by running the same test routines as during the first development alongside the test routines for the second. When the third project comes along, the first and second test suites should be run alongside the new ones for the third.
This is called ‘regression testing’ and continues as long as any part of the code is under any kind of active development. Its purpose is to ensure that changes or additions to any part of the code do not adversely effect any existing part. Amateurs very rarely, if ever, perform this kind of testing and may not even understand the necessity for it.
If an error creeps into any part of the code that is shared between projects, that error will cascade into all affected projects and, if regression testing is not done, will exist in the codebase invisibly. As more and more projects are added, the effects of the errors may spread.
The very worst possibility is that the errors in the early projects are small, but grow slowly over time as code is added. If this happens (and it can!) the wrong results will not be noticed because there is no external gauge, and the outputs may drift very far from the correct values over time.
And this is just for deterministic software, the kind where you can predict exactly what should come out as long as you know what you put in. That is relatively easy to test, and yet hardly any amateur ever does it. With stochastic software, by definition and design, the outputs cannot be predicted. Is it even possible to test that?
Well, yes it is, but it is far from easy, and ultimately the quality of the software is a matter of judgement and probability rather than proof. To get an idea of just how complicated it can be, read this article that describes one approach.
Professional testers struggle to test stochastic software adequately, amateurs almost always go by the ‘smell test’. If it smells right, it is right.
Unfortunately, it can smell right and still be quite wrong. Because of the repetitive nature of stochastic systems, small errors in endogenous variables can amplify exponentially with successive iterations. If a sufficient number of loops is not tested, these amplifications may well not be noticed, even by professionals.
I recall testing a system for ONS that projected changes in small populations. This was to be used for long term planning of education, medical, transport and utilities resources, amongst other things, over a period of 25 years. A very extensive testing programme was conducted and everything ‘looked right’. The testers were happy, the statisticians were happy, the project manager was happy.
However, shortly before the system was placed in production use, it was accidentally run to simulate 40 years instead of 25 and this produced a bizarre effect. It was discovered that the number of dead people in the area (used to calculate cemetery and crematoria capacities) was reducing. Corpses were actually being resurrected!
The fault, of course, was initially tiny, but the repeated calculations amplified the changes in the endogenous variables exponentially and eventually the effect became obvious. This was in software that had been specified by expert statisticians, designed and developed by professional creators, and tested by me. What chance would amateurs have?
There are ways to test stochastic processes in deterministic ways but these work on similes of the original code, not the code itself. These are also extremely long-winded and expensive to conduct. By definition, stochastic software can only be approved based on a level of confidence, not an empirical proof of fitness for purpose.
Stochastic processes should only be used by people who have a deep understanding of how a process works, and this understanding may only be gained by osmosis from actually running the process. Although the projection depends on randomicity, that randomicity must be constrained and programmed, thus rendering it non-random. The success or failure of the projection is down to the choice of the variables used in setting the amount of random effect allowed in the calculation – too much and the final output envelope is huge and encompasses practically every possible value, too little and the calculation may as well be deterministic.
Because of the difficulties in testing stochastic software, eventually it always turns out that placing it into production use is an act of faith. In the case in point, that faith has been badly misplaced.
Mony a Mickle Maks a Muckle
Testing stochastic software is devilishly difficult. The paradoxical thing about that is that the calculations involved in most stochastic systems tend to be relatively simple.
The difficulties arise with the inherent assumptions and the definitions of the variables implicated in the calculations. Because the processing very often involves exponential calculations (we’ve heard a lot about exponential growth over the past 24 months), any very slightly excessive exponent can quickly amplify any effect beyond the limits of credibility.
To explain how exponential growth works, here are .01, .02, .05 and 0.10 exponential growths over 25 cycles. So for .05 growth per cycle each number is increased to the power 1.05, i.e., x = x1.05. The actual ‘exponent’ is the little number in superscript.

You can see from this table what an enormous difference a very small change in exponent can make – changing from 0.01 to 0.10 growth leads to a multiplying factor of about 900 over 25 cycles.
Now imagine that these results are being used as exponents in other calculations within the same cycles and the scale of the problem quickly becomes apparent. The choice of exponent values is down to the researcher and accurately reflects their own biases in the understanding of the system behaviour. In the case of infections, an optimist may assume that not many people will be infected from a casual encounter whereas a pessimist could see an entire city infected from a single cough.
This illustrates what a huge difference a very small mistake of judgement can produce. If we had been considering the possibility of a Covid-infected person passing that infection on to another person within any week was about 10%, then by the end of six months he would have infected over 1,800 people Each of those 1,800 would also have infected 920 others, and those 920 would have infected 500, and so on and so on.
However, if the real infection rate was just 1%, then the number of people affected after six months would probably not be more than a large handful. (This is massively over-simplified and ignores things like effectiveness of treatments, seasonality, differing strains and many more factors. But then, apparently, so does Neil Ferguson’s software.)
Many of the factors implicated in such calculations simply cannot be known at the outset, and researchers may have a valid reason to err on the side of caution. But in normal circumstances a range of scenarios covering the most optimistic, most probable and most pessimistic states would be run, with confidence levels reported with each.
As time passes and real world data is gathered, the assumptions can be tuned against findings, and the model should become more accurate and better reflective of the real world. Unfortunately, there is precious little evidence that Neil Ferguson ever considers the real world as anything other than incidental to his activities.
Remember that what we are considering is a code monolith – a single huge collection of programming statements that has been built up over many years. Given that the codebase is built up of C++, Erlang and R routines, its development may well have begun at the tail end of last century. It is extremely likely that its oldest routines formed the code that was used to predict the expected outcome of the 2001 outbreak of foot and mouth disease in the U.K. and it has been steadily growing ever since.
To gauge just how good its predictive capabilities are, here are some notable mortality predictions produced using versions of this software compared to their real-world outcomes. (An order of magnitude is a factor of 10 i.e., 100 is one order of magnitude greater than 10.)
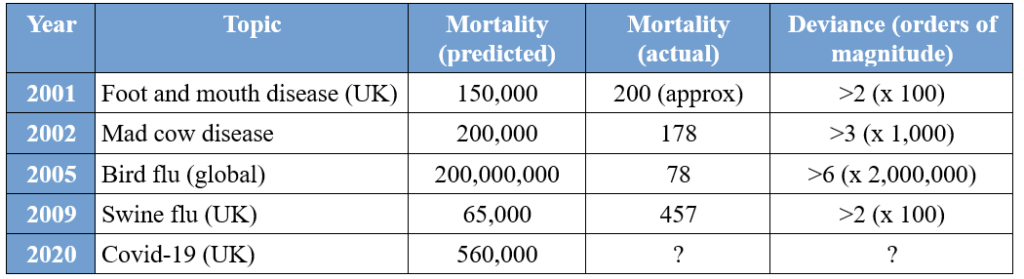
As we can see, the models have been hopelessly pessimistic for more than two decades. We can also see that, if any review of the model assumptions had ever been carried out in light of its poor predictive performance, any corrections made haven’t worked.
It appears that the greater the expected disaster, the less accurate is the prediction. For the 2005 bird flu outbreak (which saw a single infected wild bird in the U.K.) the prediction is wrong by a factor of over 2,000,000. It’s difficult to see how anyone could be more wrong than that.
I haven’t included a number for COVID-19 mortality there because it has become such a contentious issue that it is very difficult to report or estimate it with any confidence. A widely-reported number is 170,000, but this appears to be for all deaths of/with/from/vaguely related to COVID-19 since January 2020. In 2020 in England and Wales there were about 60,000 more deaths than in 2019, but there were only 18,157 notifications to PHE of COVID-19 cases, some, many or most of whom would have recovered.
As a data professional, it has been heartbreaking to watch the perversion, indeed the subversion, of data collection processes over the past two years. Definitions and methods were changed, standards were lowered and even financial inducements apparently offered for particular classifications of deaths.
Don’t Look Back in Anger – Don’t Look Back at All
I noted above that there seemed to have been precious little feedback from the real world back into the modelling process. This is obvious because over the period since the beginning of this panic there has been no attenuation of the severity of the warnings arising from the modelling – they have remained just as apocalyptic.
One of the aspects of the modelling that has been slightly ignored is that the models attempted to measure the course of the viral progress in the face of differing levels of mitigations, or ‘non-pharmaceutical interventions’ (NPIs). These are the wearing of face masks, the closure of places where people would mix, quarantines, working from home, etc. In total there were about two dozen different interventions that were considered, all modelled with a range of effectiveness.
The real world has stubbornly resisted collapsing in the ways that the models apparently thought it would, and this resilience is in the face of a population that has not behaved in the way that the modellers expected or the politicians commanded. Feeding accurate metrics of popular behaviour back into the Covid models would have shown that the effects expected by the models were badly exaggerated. Given that most people ignored some or all of the rules and yet we haven’t all died strongly suggests that the dangers of the virus embodied in the models are vastly over-emphasised, as are any effects of the NPIs.
On top of this we have the problem that the ways in which data was collected, collated and curated also changed markedly during the first quarter of 2020. These changes include loosening the requirements for certification of deaths, removing the need for autopsies or inquests in many cases, and the redefining of the word ‘case’ itself to mean a positive test result rather than an ill person.
At the start of the panic, the death of anyone who had ever been recorded as having had Covid was marked as a ‘Covid death’. This did indeed include the theoretical case of death under a bus long after successful recovery from the illness. Once this had been widely publicised, a time limit was imposed, but this was initially set at 60 days, long after patients had generally recovered. When even the 60-day limit was considered too long it was reduced to 28 days, more than double the time thought necessary to self-quarantine to protect the wider population.
There are other problems associated with the reporting of mortality data. We noted before that only 18,157 people had been notified as having a Covid diagnosis in England and Wales in 2020, yet the number of deaths reported by the government by the end of the year was about 130,000. It seems that this includes deaths where Covid was ‘mentioned’ on the death certificate, where Covid was never detected in life but found in a post mortem test, where the deceased was in a ward with Covid patients, or where someone thought that it ‘must have been’ due to Covid.
Given the amount and ferocity of the publicity surrounding this illness, it would be more than surprising if some medical staff were not simply pre-disposed to ascribe any death to this new plague just by subliminal suggestion. There will also be cases where laziness or ignorance will have led to this cause of death being recorded. If, as has been severally reported, financial inducements were sometimes offered for Covid diagnoses, it would be very surprising if this did not result in many more deaths being recorded as Covid than actually occurred.
Conclusions
Stochastic modelling is traditionally used to model a series of possible outcomes to inform professional judgement to choose an appropriate course of action. Projections produced using modelling are in no way any kind of ‘evidence’ – they are merely calculated conjecture to guide the already informed. Modelling is an investigative process and should never be done to explicitly support any specified course of action. What we have discovered, though, is that that is exactly how it has been used. Graham Medley, head of the SAGE modelling committee and yet another professor, confirmed that SAGE generally models “what we are asked to model”.
In other words, the scientists produce what the politicians ask for: they are not providing a range of scenarios along with estimates of which is most likely. Whilst the politicians were reassuring us that they had been ‘following the science’, they never admitted that they were actually directing the science they were following.
To demonstrate how different from reality the modelling may have been, we can simply examine some of the exogenous variables that are hard set in the code. In one place we find an R0 (reproduction) value of 2.2 (increasing quickly) being used in May 2020 when the real R0 was 0.7 to 0.9 (decreasing) and in March 2021 a value of 2 (increasing quickly) was being modelled when the real-world value was 0.8 to 1.1 (decreasing quickly to increasing slowly). Using these values would give much worse projections than the real world could experience. (As an aside, defining the same variable in more than one place is bad programming practice. Hard-coding is not good either.)
This admission has damaged the already poor reputation of modellers more than almost anything else over the past two years. We always knew that they weren’t very good, now it seems they were actively complicit in presenting a particular view of the disease and supporting a pre-determined political programme. Why they have prostituted their expertise in this manner is anyone’s guess but sycophancy, greed, lust for fame or just simple hubris are all plausible explanations.
One of the most serious criticisms of the Covid modelling is that it has only ever modelled one side of the equation, that of the direct effects of the virus. The consequential health and financial costs of the NPIs were never considered in any detail but in practice seem likely to hugely overshadow the direct losses from the disease. No private organisation would ever consider taking a course of action based on a partial and one-sided analysis of potential outcomes.
Wouldn’t it have been good if the software used to justify the devastation of our society had been subject to at least a modicum of disinterested oversight and quality assurance? Perhaps we need a clearing house to intervene between the modellers and the politicians and safeguard the interests of the people. It would surely be useful to have some independent numerate oversight of the advice that our legal or classically-trained politicians won’t understand anyway.
The best thing that can be said about the modelling that has been used to inform and support our Government’s response to the Covid virus is that is probably much better quality and of higher integrity than the nonsensical and sometimes blatantly fraudulent modelling that is ‘informing’ our climate change policy.











To join in with the discussion please make a donation to The Daily Sceptic.
Profanity and abuse will be removed and may lead to a permanent ban.
Tis posited in certain learned circles that infact, certain batches of the cytotixic concoction are fekin lethal!….Democide!
Exactly. Fawning over numbers derived from fake PCR tests to determine some phantom ‘efficacy’ value, when the jabs themselves are causing serious illness and death.
Indeed.
5% of batches ACROSS manufacturers are responsible for 100% of vaccine (they’re not) damage and deaths in global populations.
It would also seem that the manufacturers stagger the deployment of the damaging lots.
Some are saying this is baselining toxicity.
‘Some’ are probably right- we seem to be in very great danger!
Yup, I am a ER1741 “Pfizervivor” ( immune compromised for those who think “why jabbed”)
Interesting, I would like to book a holiday, however unfortunately due to not being particularly interested in current affairs I was completely unaware that one is now apparently required to have up to three I think they’re called fizzer jabs in order to travel abroad if so, can someone please advise where one can get all three of the non democide variety at the same time. Many thanks in advance.
Check out this website
https://howbad.info/
Yes at last this is getting out!
What I fear most now though, as the sheep begin to wake up, is that they will invent another “Deadly Variant” with some prepared horror footage and a new mass fear pumping campaign offensive to justify Total Lockdown and armed police on the streets!
Please let me be wrong!
On the brighter side, it seems that ‘Porker’Johnson might not declare War on Russia after all – in the end I suppose it depends on what his Consigliere tells him to do.
The boredom factor must be setting in now, Klaus Schwab talked about the small window of opportunity, the question is have they already succeeded or can a belated backlash stop them.
Let us hope that bricks have broken his “small window”!
@David – Who do you mean by his consigliere?
Carrie !
Cue Clive Myrie…
“learned circles”…. where the learning is wrong.
Yawn.
I was just typing a reply to another commenter who used a bad word in reply to ‘rational’ and whoosh, his comment and my reply disappeared down the memory hole. I expect it’s a glitch.
Can I suggest that everyone flags him as a troll?
You are funny.
Yet you are profoundly incapable of demonstrating why it is.
The old fashioned flu vaccine diminishes over time, thats why you have a shiny new one ever year. Why are we shocked that the Covid one does likewise.?
Well, let’s see… just one idea …because the ‘effectiveness’ of the covvie snake oil vanishes after ten weeks?
Nobody that’s been following this is “shocked”. A few points:
I could go on, but, quite frankly, I can’t be arsed. Go and do your own research… or do they not allow that in the barracks?
I’m sure the barracks are very tight on ‘unapproved ‘ information entryism.
I’m a pharmacist and the reason is because it’s a different strain or strains in it every year, this year there were 4 strains. I’m sure it does become less effective over time but that’s not why we are supposed to get it year on year.
I don’t agree with the covid injection (it’s not a vaccine, it does not stop transmission or infection) I had flu jab every year, I’m thinking of not having any more.
Yes,me too!
Hi Rob, I got your DM. Thank you. I understand and accept what you’re saying. I’m probably just a little tired of seeing more and more graphs that prove this or that, that prove nothing much and nanobots, and ‘killer batches’, and world domination, and a lot of the groupthink that follows. I’m not having any more of the covid vaccines either. It seems to have had a momentary usefulness, but things have moved on and that is no longer the case. Everyone can and should make that choice for themselves.
ATB. Neil
I’ve only ever had a couple of flu jabs, but this year I ignored the invite because I simply didn’t trust what might be going into my arm, what with No. 10’s determination to have us all Pfizered up.
Probably won’t trust them ever again after all the nonsense they’ve pushed on us over a virus that would have seriously affected around 1% of the population.
Less than 1% seriously affected.
Even Whitty, at the start, predicted that 80% of the 1% affected, wouldn’t die of it:
Chris Whitty- Government Daily Briefing 11/05/2020.
“A significant proportion of people will not get this virus at all, at any point of the epidemic which is going to go on for a long time.
Of those who do, some of them will get the virus without even knowing it, they will have the virus without even knowing it, they will have the virus with no symptoms at all- asymptomatic carriage, and we know that happens.
Of those that get symptoms, the great majority, probably 80%, will have a mild or moderate disease,-might be bad enough for them to have to go to bed for a few days, not bad enough for them to have go to the doctor.
An unfortunate minority will have to go as far as hospital, but the majority of those will just need oxygen, and will then will leave hospital, and then a minority of those will end up having to go to severe and critical care, and some of those sadly will die, but that’s a minority, it’s 1% or possibly even less than 1% overall, and even in the higher risk group..Uh..this will be significantly less than 20% i.e. the great majority, even the very highest groups, if they catch the virus will not die”.
Any idea what 1% of the population amounts to?
This is the only comment I’m going to make to you, as you are clearly a troll.
Whitty didn’t state that 1% of the population would catch it – indeed, he admitted that it could well be under than 1%, and so it proved.
Looking at the ONS stats for England and Wales, in each year of the ‘pandemic’ about 6,000 very old people died solely of Covid-19 – average age 81+.
There was no need to lockdown or have mass ‘vaccination’ for such an unthreatening virus.
Why are people focussing Pfizer vaccines in particular?
What is your definition of a vaccine?
Please give references to a reliable source to support your statement.
A vaccine stimulates the production of antibodies directly.
(And no sealioning effort in response, please.)
The flu jabs made a contribution to softening up minds ready for the SARSCoV2 jabs. Rather than getting flu-jabbed every year, you’d be better off taking a wallop load of vitamin C every day, @Rob.
What’s your take on the decision not to call the above-mentioned strain of SARS a strain of SARS?
Hell, the four flu strains to which you refer aren’t even in the same genus, let alone the same species, and yet they’re still all called “influenza”.
If we needed one, this is a fine example of what things are called being important – far more important than many realise.
The flu vaccine is a different one each year based on the most prevalent strains in the other hemisphere, AFAIK. The covid “vaccine” is just multiple doses of the same thing, so far.
“The covid “vaccine” is just multiple doses of the same thing, so far.”
That will change.
Also, your life, movements and travel are not restricted by ‘how up to date’ you are with you flu vaccine.
Not shocked that it is a dud but shocked that the world is basing so many measures on it’s lack of effectiveness.
The 4th Industrial humiliation… Sarigan
We’re all digital Auschwitz inmates now, having to increasingly carry 24/7 vaxx passes to officially endorse that we’re not active viral vectors…a tenuous privilege that can be rescinded at the swift flick of a keyboard key due to bogus case crises.
Remember the Old Normal? When people just traveled freely about, internationally too with a level of dignity and personal privacy – simple acts that were once considered a basic human right, now seemingly gone for good?
While 80% of the UKs populace has willing complied with the coercive Covidian cult New Normal dictates… the rest of us not hoodwinked sadly swept along with the wave of technofcism this brings.
Our job? To keep kicking and screaming against this Orwellian WEF/globalist narrative, and converting those that are awakened by glimpses of hidden truths behind the twitching propaganda curtain.
However, I do personally find it hilarious that they actually think of themselves as elites…. as if.
https://twitter.com/ConceptualJames/status/1484355983082094598?s=20&t=CDqsCRr8JOBMsmCuEveKgw
Finally, some further weekend lite relief… Happy Saturdays!
https://twitter.com/HattMancockMP
Flu ‘vaccines’ are pretty useless also, see –
https://www.cochrane.org/CD001269/ARI_vaccines-prevent-influenza-healthy-adults
Sorry, but you completely miss the point and sadly do nor seem to understand what the Covid injection contains and what it actually does to the body..
The action of the synthetic spike protein on the cells involves entering them to initiate stimulate this same spike protein’s reproduction – this has been fully explained in great detail many times by eminent virologists and I really cannot see why there is any excuse for not knowing that .
An experimental mRNA Gene Therapy which this most definitely is, cannot be exected to act like a traditional ‘vaccine’ which it is not, in spite of attempts to change the definition of the term ‘vaccine’ to allow its inclusion for propaganda purposes.(ie “it’s just an ordinary vaccine” as a nurse once said to me)
All this is now common knowledge..
The complicity (or ignorance) of the medical profession in preaching and administering this so-called vaccine might signal the end of the public euphoria over the sainted NHS.
If so, they’ll only have themselves to blame.
A note for the benefit of younger readers: the BMA opposed the creation of the NHS.
Nobody who was paying attention to the vaccine discussion very early on in the spring of 2020, before debate was censored, would be shocked at all.
Because one of the things that kept coming up was the fact that for decades they had been trying and failed to produce vaccines against coronaviruses.
And the reason given for the failure was that it just mutated too quickly.
But then, the pharma cartels and the media (same owners) got to work with the hard sell of the mRNA vaccine and the rest is history.
Vaccines against coronaviruses don’t work because the virus mutates even quicker than influenza viruses. So they are even more ineffective than flu jabs.
Yes all the evidence supports the fact that the covid vaccines work well against severe infection and death.
The point is that with very very few exceptions, the people who suffer from severe infection and risk of death are easily identified. They are overwhelmingly elderly with multiple comorbidities; the rest are extremely obese.
If the vaccine program was simply aimed at this group following the advice of the ‘great barrington’ group, and there was sufficiently good monitoring of reactions etc after vaccinations, there would be disagreement still about using emergency use mRNA vaccines, but basically there could be justification on the basis of risk/reward.
But this was not done. And the ridiculously politically inspired compulsory and pseudo compulsory mandates around the world for all and sundry including children are vile and evil.
It really doesn’t matter what words you write to try to excuse this, they will fail to convince anyone that has any knowledge of the situation.
Please stop your endless , frankly empty rhetoric simply designed to satisfy your own ego. You are a sad individual whatever your motives.
Really? So what is the risk of dying of covid for a 40 year old who is vaccinated and for one that is unvaccinated?
And all the evidence confirms that early treatment with repurposed drugs – many out of patent and therefore very cheap – works even better to prevent viral loads from escalating and keeps people out of hospital – not my experience but that of thousands of Doctors world wide. So “vaccines” have been a massively expensive, and medically irrelevant exercise in pumping taxpayer money to the global Pharma cartel, let alone the death/adverse health effects they have caused, from the jabs directly and indirectly, the untold economic damage and eye watering increases in national debt (all unnecessary).
Happy with that level of collateral damage? Happy with the inflammatory and clotting reactions of the jabs – and the long term damage thereof?
Propaganda isn’t evidence.
Flu vaccines are a cocktail of various flu viruses that have been weakened. There are a very large number of flu virus varients and the WHO decide months in advance which variants of the flu virus is likely to be dominant for the coming winter.
The flu vaccine is weakened flu viruses, the so called Covid vaccine isn’t weakened covid virus it mimics part of the virus.
We’re not shocked that the effectiveness of the supposed Covid vaccine is going from positive effectiveness to less positive effectiveness like old fashioned flu vaccine.
We’re shocked that it is going from negative effectiveness to even more negative effectiveness and still being administered.
A) Not a vaccine, as sterilising capacity ….lets be kind, “very very limited”;
B) Drug developed from original Alpha SARS COV2 – not approved, still experimental and very shoddily tested;
C) Induces a version of the Alpha spike protein, but apparently not an identical copy merely an approximation;
D) Does not address the full viral antigen spectrum of the Alpha version;
E) Causes death, serious adverse effects, and hospitalisation on a massive scale;
F) Appears to allow other variants to “dodge” the jab;
G Study after study after study shows natural immunity to be more effective and far far more efficacious than any jab.
H) Reduction of severe symptoms very short lived, exposing the person to further variants.
And to top that, patient treating Doctors across the globe have combined to share their clinical experience to design and refine early treatment regimes using a very wide range of repurposed antivirals/antihistamine/antibody monoclonal infusions and a load more. The initials AAPS, FLCCC, AFLD, BIRD, TDC19,PANDA, CMN are the antidote to WHO/FDA/NIH/CDC/EMA/SAGE/NERVTAG/iSAGE/UniNC. These Doctors have treated millions of people with great success in reducing severity, hospitalisation and death.
Just think, why have the Chinese, according to these Doctors, been so successful using IV Vit C – could it be that it is very effective in boosting your immune system?
Just think, why has the “top” government medical official in the US and the UK, apparently NEVER mentioned one word about essential vitamins and minerals as a beneficial way for people to self treat prophylactically?
If any mindless “vaccine”lovers don’t yet realise, SARS COV2 and CV19 has produced without ANY doubt the greatest acts of corrupt and sustained criminal behaviour in human history (by involving the entire population of this planet – and that should scares rigid) by so called governmental health agencies aided and abetted by very powerful, individuals hell bent on changing the way people live , al la “Globalisation” scam beloved of Blair and the rest – working for the pharmaceutical industry, social media, government quangos and the MSM. It hasn’t just happened since mid 2019.
As many have stated, it is not about health; this has been a fraudulently driven event by “cases” – a very obvious device to hype what actually is the case – just think about the OFFICIAL ONS data of deaths in the UK where no other comorbidity is mentioned = <20,000, compare that to “deaths within..” ; unsuspecting innocent people have been treated as human petrie dishes, herded into hospital by official diktat – because they were denied early treatment when infected – burdened with a much higher viral load that was totally avoidable, allowed to become far sicker which meant they infected others and required much greater medical intervention and treatment, putting massive pressure on an already stretched NHS; some of them were herded back to Care Homes and the death toll here and in the US was massive as a result ( the two biggest sources of acquired infection in the UK…..Hospitals and Care Homes) . All this was decided by politicians incapable of grasping the detail, and heavily and malignly influenced by people who know better but chose to abandon their morals, ethics and duty of care – Whitty, Vallance, van Tam, Raine, Harries, Ferguson, SAGE, Nudge Unit criminals.
So for all the talk about “vaccine” efficacy, RRR, ARR, and other facets is all irrelevant against “the bigger picture”. All of the above is not original – others have been saying this for a very long timed vilified for speaking the truth; how strange that TPTB now appear to realise the “gates is up”…..I hope there is “no hiding place” for any of these “players”; I for one will never forget their role in “this”; I would like to propose a “Hall of Shame” and the first nominee is Dr Anthony Fauci.
:scare you “…..”game”…oh dear.
I compare vaccinated (any number of doses) with the unvaccinated, as since very few first doses are going on it doesn’t have potential mis-allocation issues, and to state the obvious to get to the third dose state you have to travel through the first dose and second dose states first.
On this basis still negative efficacy against testing positive in every age group when comparing unvaccinated vs vaccinated (any dose). See attached chart.
Slight improvement in younger age groups (coloured green), less negative efficacy.
Middle ages (coloured gold) following their levelling off trend, at well over double the rate of +ves in the vaccinated vs the unvaccinated.
Efficacy against testing +ve still worsening in the oldest age groups (coloured red) i.e.greater negative efficacy but worsening is easing off and may level off next week perhaps.
All cause emergency care admissions is what we should be comparing between the vaccinated and unvaccinated, rather than emergency care admissions with a +ve test.
If we have more people being treated in hospital for adverse affects of the vaccines (and this usually happens without a positive test) than are being treated for covid the illness (a positive test with accompanying symptoms) then how can looking narrowly at positive test admissions give any information on how well the experimental vaccines are really doing?
But to the extent to which those +ve test emergency admissions show how little impact the unvaccinated are having on hospitals in relation to SARS-C0V-2 let’s look at the figures.
+ve test emergency care admissions levelling off in absolute numbers in the latest 4 week period. 32.4% of +ve test emergency care admissions are in the unvaccinated.
Top and bottom chart are the same but vaccinated (any dose) are on the top in the top chart and on the bottom in the bottom chart, and labels are percentages of admissions that are in the vaccinated (any dose) and unvaccinated in the top chart and the absolute numbers in the bottom chart.
And to illustrate the difference between positive test hospital cases and those with a positive test actually being treated ‘for covid’
From the primary diagnosis supplement published by the NHS this week and reported on in an earlier daily sceptic article.
Patients in England being treated for covid (by the official definition not mine) less than half of all +ve hospital patients as at 25th January and proportion still falling.
Both +ve test hospital numbers and treated ‘for covid’ numbers clearly falling.
See new list of 52 viral traces included in the PCR test spectrum along with SARS Cov 2.
The ‘positive result’ PCR test is a total fraud – it could be based on one of 53 virus traces – who knew?
In any case it does not identify infection .
Thanks FC…screenshot…nice and easy to understand.
All cause deaths is what we should be comparing between the vaccinated and unvaccinated, rather than deaths within 28 days of a positive test. If we have more people who have died due to adverse affects of the vaccines (and this category of death usually happens without a positive test) than have died from covid the illness (a positive test with accompanying symptoms that cause the death) then how can looking narrowly at positive test deaths give an accurate picture of how the experimental vaccines are really doing?
We only have to look at sportsmen to suspect that vaccine related deaths are very significantly more common than covid deaths, at least in that healthy population. How many athletes died of covid in 2020 before the experimental vaccines?
The ONS all cause death data by vaccination status suggests that in absolute numbers around 5% of all all cause deaths in England are in the unvaccinated and 95% in the vaccinated. That’s based on October 2021 where the data currently goes up to.
But again working with the +ve test deaths as that’s all UKHSA provide:
The attached chart shows we are down to just 22% of within 28 days of +ve test deaths in the unvaccinated. No increase in +ve tests deaths in the unvaccinated but an increase in the vaccinated for the latest 4 weeks.
Fair point, but don’t you really need to do this in age bands – the young are more likely to be unvaxxed and less likely to die so this will skew the figures.
It depends what we are trying to illustrate.
If we are comparing all cause deaths to estimate efficacy against death, then yes we would compare this in age bands to see if the vaccines were causing net harm or net benefit. And then we might adjust for other health and other differences between the vaccinated and unvaccinated.
If we are trying to illustrate numerically how little impact the unvaccinated have on the health service in relation to SARS-C0V-2, and how that impact varies over time between the vaccinated and unvaccinated in terms of the number of +ve test deaths, then that’s a different thing. And that’s the aim of my chart. It helps counter the nonsense of 90% of ICU being filled with the unvaccinated, when only 22% of the +ve test deaths are in the unvaccinated. And then most of ICU is occupied by non positive test patients in any case.
Why don’t I like to compare efficacy of the experimental vaccines against death within 28 days of a positive SARS-C0V-2.test?
Well let’s look instead at the harms side of the balance sheet rather than benefits side. We might say not taking the vaccine has 100% efficacy against avoiding adverse vaccine reaction. We can see that is a silly comparison because it only looks at the benefits of not taking the vaccine and not the potential harms of not taking the vaccine.
But why conversely should I only look at the potential benefits of the vaccines in preventing a death being labelled as covid and ignore the harms. I prefer not to fall into that trap of framing the discussion into one about potential vaccine benefits only and ignoring the harms.
More likely to die of the vax than Covid though, as the figures themsleves now show,
Can we use this data to generate ‘best advice’ for people in various situations?
For instance, what should someone with one vaccination do? What should someone with two vaccinations do? etc .. ..
Yeah, this is something I struggle with. I’m unvaxxed, but my wife had two very early on (she works in healthcare) before she realised the whole thing is a sham, so she won’t have the booster. The data looks clear – better in the short term to have the booster if you’re already double jabbed. But you’re then just committing to be forever jabbed. But if you don’t, the data doesn’t look good. Damned if you do, damned if you don’t. I’m hoping that the immune system will eventually kind of reset if left to its own devices for long enough. I hope I’m right
Ditto…..I have friends and family in the one, two and three jab category, and it is a worry. On the whole better not to get the booster I think and hope that the body ‘eliminates’ what it can, and hope the jabs are as useless in this as they seem to be in everything else.
whatever the vaccines efficacy it is still true, and more so with Omicron, that
the vast majority of us will not get a serious bout of Covid so I can see no reason to get more jabs. The IFR for Omicron for anyone under 50 is 0.0% according to John Ioannedes, and it’s not much higher for anyone else….
Personal experience only, I know but I had my second dose (Astra zenica) well over 6months ago. Haven’t bothered with a third because I don’t trust Pfizer.
Thought I had a cold a couple of days ago and I had to do a test yesterday (school protocol) which turned out positive.
Without wishing to tempt fate, feeling great today.
I tried to milk it as man flu but my wife was having none of it…
Ten days house arrest now, for a sniffle.
Your post illustrates why I really hate these 2 dose vs 3 dose comparisons. It gives the false impression that having the third dose is a good idea if you’ve already made the mistake of having the first 2 doses.
However the higher 2 dose vs 3 dose rate is probably not a real affect at all, or at the very least if it exists at all it hugely overstates any real effect. There are also potential harms of the third dose in further setting up original antigenic sin, as well as increasing the risk of auto-immune disease.
So why are these comparisons misleading and lead to this mis-conception that the third dose is a good idea if you’ve had 2 doses already?
Firstly the UKHSA allocate emergency care admissions with a positive test within 14 days of the third dose, with hospitalisation happening within a further 28 days to the second dose emergency care admission category. Someone might have the third dose, test positive 13 days later and then get hospitalised 22 days after that. So even though their admission is a full 5 weeks after their third dose their hospitalisation gets allocated to the second dose category, which can then fall within the pat 4 week comparison period.
Secondly and probably more importantly, a very small proportion of those who had two doses of vaccine in the older age groups, did not go on to have the third dose. That leaves behind in the second dose category, a number of seriously ill people who are too ill to have the third dose. As numbers in the exactly two dose category reduce those seriously ill people become disproportionately a relatively large proportion of the two dose category. And so second dose rate of emergency care admission/death go up massively relative to third dose rates.
However a healthy person who has had two doses of vaccine, but realises that the vaccines are hugely dangerous doesn’t suddenly change their health from the average health of a person in the second dose category (poor) to the average health of someone in the third dose category (relatively much much better). Instead their health stays the same.
So the two dose bad vs three dose is most likely a complete illusion, although it’s impossible to say for sure.
Here’s a tweet with photo that should settle the question for anyone on the booster fence.
More shocking images like this are emerging every day – there is a huge scandal brewing!
I think this is an important point. If we stop jabbing people further, will their immune systems recover back to normal (and over what time period) or are they now permanently damaged?
Well you first have to start looking at what’s really in the jabs. Have you been watching anything by La Quinta Columna?
Nano-graphene, self-assembling nano-particles, various parasites some of which they can’t identify. These jabs are a frankenstein horror mix of God knows what, but it’s easier to believe all that is just nonsense conspiracy theory. The batch data proves the vials are different, that should be your starting point.
Geert Vanden Bossche suggests NOT taking further boosters might or should allow the immune system to ‘reset’ itself. According to him, vaccinal antibodies will outcompete innate immunity. – even if they are ineffective
This blog post gives a brief explanation though you’ll probably need to go through other posts to gain full understanding.
https://www.voiceforscienceandsolidarity.org/scientific-blog/like-a-virgin-untouched-forever
Where is Whitty? Seems to have gone a bit quiet since his ‘Knighthood’!
Preparing his defence for a gross professional misconduct charge brought by the GMC following his scandalous appearance in the NHS “propaganda” video amongst other acts of mendacity – hopefully….?
I must admit to being confused as to why a post asking for ‘the best advice’ should get a thumbs down. Does someone believe that good advice should NOT be given? I’d love to hear from them what they disagreed with….
Best advice is to ignore the vast majority of what is written here.
Go to a reliable source.
So, literally, the exact opposite of what you’re doing.
You should really follow your own advice.
He is too busy following orders!
Wonder upon wonder – I am one of your “vanishingly small” upticks as that is the most sense I have seen today.
May I recommend Doctor Peter McCullough to you?
The flu jab didn’t stop death,it didnt even stop the flu, for most people getting a really bad dose of the flu after the jab, confirmed to them that the jab was working, ie “they infect you with the virus going around that’s why I’ve got it” . The info about this jab is as clear as mud although getting symptoms and feeling rough after seems to make people feel the same way, its working .
I know that causality isn’t causation, but the first graph at the top clearly shows that celebrating Christmas leads to these “vaccines” not being as effective.
Maybe this a good reason to ban Christmas – just to be on the safe side.
Probably best to ban Chinese New Year, too, since it seems to have kicked off this whole Wu-flu thing?
You might want to check your dates.
Now that 52% of hospital admissions ‘with’ Covid are being admitted for something else. Is it not likely that the ridiculous classification system is coming back to bite them on the a/se?
Same with the deaths ‘for any reason within 28 days’ nonsense could be skewing the vaccine effectiveness against death (because they are including deaths that are actually totally unrelated).
The UKHSA have been well and truly hoist by their own petard, so to speak.
Fat chance that governments&co will ever accept that.
Just 2 days ago Don Karleone stated that getting vaxxed is far less risky to a healthy 30 yr old than getting infected with Omicron.
I think he really believes that.
The problem in practice, as described by HC workers on a German HC worker T channel is that getting hospitalised vaccinated is just fine, but if getting hospitalised unvaccinated, you are treated like a criminal, if at all.
The imposition of mRNA vaccines on the population is one aspect of a combination of policies that collectively amount to a State-sponsored holocaust. Listen to Senator Johnson’s riveting 5-hour hearing of 24 January.
https://www.redvoicemedia.com/video/2022/01/live-covid-19-a-second-opinion-ron-johnson-moderated-panel-discussion-with-experts/
The reason why 800,000 died from covid in the USA and 150,000 in the UK is that the medical authorities deliberately prohibited early treatment of the disease using generic drugs. The NIH over there and NHS over here forbade early treatment, using ivermectin, hydroxychloroquine etc – inexpensive, generic drugs – and instead let the infected wait until they were so ill that they had to go to hospital, when they were prescribed, in the US, the toxic drug remdesivir and hopelessly inadequate doses of the steroid dexamethasone, then put on ventilators and in many cases left to die.
As Bartram’s analysis is indicating, the vaccines are also killing people through increased risk of dying from covid. They’re also killing through their side-effects.
And yet, despite this “negative effectiveness” last reported 75% of ICU patients in Germany are unvaccinated. It must be a miracle!
Cite or shaddup
Hospitalization in 60+ age group (per 100000) in second week of 2022 by vaccination status in Germany:
unvaccinated: 16.3
vaccinated 2x: 3.2
boostered: 1.4
How’s that about “negative effectiveness”, Sherlocks.
Source: RKI weekly report – https://www.rki.de/DE/Content/InfAZ/N/Neuartiges_Coronavirus/Daten/Inzidenz_Impfstatus.html
Globally moron?
Was only a few weeks ago that German data showed the jabbed were 8x more likely to test positive with Omicron, and jab efficacy was down to -87%.
As I understand it, in Germany you’re only considered ‘fully vaccinated’ if you’ve had 2 doses of the Pfizer/Moderna/Astra jab or 1 dose of the J&J jab.
If you’ve only had 1 dose of anything other than J&J you are classed as ‘unvaccinated’.
Also, if you require hospitalisation within 14 days of the injection date you are classed as ‘unvaccinated’ like you are in the UK.
How many of those German ICU beds are vaccine adverse reactions from single doses and within 2 weeks of being injected?
And of course those deemed too fragile to have the jab
Also rayc if you don’t mind, can you please verify the subtitles on this video are correct?
Exactly! Good post!
It appears to support the fact that all the anti-vaxx stuff is nonsense.
The fact that you quote numbers and reference real information will confuse the population of this site and they may get angry.
Yes, the anti-vaxx stuff is nonsense, but vaxx stuff for younger age groups is even greater nonsense – as can be also inferred from the very official numbers concerning hospitalizations and deaths. I hope this clarifies matters for you.
Why don’t you emigrate to Canada, Australia or New Zealand where your ridiculous new world order views would be welcomed?
And you believre them…I expect you also believe German media …the infamous “Lugenpresse”!
A miracle would be if rayc engaged brain before setting out! {Yeah, I don’t believe in miracles either}
Instead of attacking the poster, why no try facts and reasoning to challenge the assertion. Would not be too hard if you were correct and could prove it..
Putting aside your ludicrous percentage, over 99% of people were never going to be in an ICU anyway – jabbed or not
Are you suggesting 1% are going to the ICU?
That should be a worry…..
No, more like 0.05% … and that’s counting over 2 years.
No i’m not suggesting that, as is clear from my comment.
Did you forget the “ir” at the start of your username?
What is the absolute number?
2223
And of those how many are in hospital because of covid, not for something else and happened to test positive?
The real question should be what is the absolute number of vaxxed people in hospital and what is the absolute no. of unvaxxed.
It looks like the Germans are using the same sleight of hand as the Dutch. In NL the public health authority has 4 graphs of different age groups with the absolute numbers – vaxxed and unvaxxed run virtually parallel, with the 3 graphs of age cohorts under 70 (I think under 20, 20-49, 50-69) showing unvaxxed at slightly higher absolute numbers – but not by much, it looks very close to 50-50. The graph for 70+ shows a split of what looks more like 70% vaxxed to 30% unvaxxed (these are graphs for hospitalised with/from corona).
There are then 4 more graphs, adjusted to vaxxed/unvaxxed per 100,000. Bear in mind near 90% of the population over 18 is double-jabbed. In all 4 graphs the unvaxxed line is significantly higher, making it appear as if approx. 80-90% of the group in hospital is unvaxxed – including the 70+ group. So like the vaxx itself, these graphs only show a relative effectiveness – the absolute number of vaxxed in hospital is greater than the absolute number of unvaxxed, but by comparing the number as a relative number from the 2 groups vaxxed/unvaxxed, the pretty pictures make it look like the unvaxxed significantly outnumber the vaxxed. Very sneaky.
The better and fairer comparison would surely be to take the number of vaxxed positive testers/unvaxxed positive testers (so let us say 1000 vaxxed test positive, 1000 unvaxxed test positive) and see what percentage from each group ends up in hospital. My guess it would be pretty much 50-50, or vaxxed would be higher.
These are ICU numbers, and they are for COVID. About half of that number is on ventilators, which is consistent with what has been observed throughout the entire pandemic. In Berlin 18% of ICU beds are now occupied by COVID patients (that’s a record number in Germany – elsewhere it is as “low” as ~7%). Utilizing more than 10% ICU beds at any given time is known to cause capacity problems.
In a population of 83 million, it’s really not a meaningful number.
0.002% of the population. Terrifying stuff.
Or simply a lie.
Presumablu in Germany to be “vaccinated “means three or four jabs – many may still have had only one or two and are therefore classed as’ un-vaccinated”!
75% of how many ….100?
Exactly what are the conditions being treated and with what protocol?
“Infection rates are soaring in the unvaccinated”
I can’t pretend to understand much of the statistical analysis above, I can only relate to personal experience. Since last summer, I now know 17 people personally-all double jabbed and some triple jabbed-who have tested positive for Covid, because I have been keeping score. Some of them were even ill with it!
However, from 11th February, people like them will be able to travel from other countries to England without taking any tests or isolating and will only have to produce a passenger locator form.
I, on the other hand, will need to test before I arrive and when I get back in addition to the passenger locator form.
That assumes I will be allowed to travel to other countries in the first place but there are still a few who will accept proof of a negative test instead of jabs.
My question to the government is why am I more of a “threat” to England than the triple jabbed?
Because, depending on your age, you may be up to 10x more likely to end up in hospital than if you were vaccinated. Thanks for asking.
Of course, the same argument applies to that obese person who sat next to you on your last flight and whose body mass encroached on your personal space. And yet such folk suffer little or no discrimination when travelling – indeed, sometimes they receive more consideration than the normally-sized.
Would you like the obese to be discriminated against next? You just wait…
Cite or shaddup
Didn’t realise you were the government rayc. Can you post a link to the above please?
I already posted it, but you are too lazy to find it, so here it is again (hospitalization rates by vaccination status in Germany):
https://www.rki.de/DE/Content/InfAZ/N/Neuartiges_Coronavirus/Daten/Inzidenz_Impfstatus.html
Do you have stats from a civilised nation?
I guarantee I’m not at all likely to end up in hospital, I’ve had about one day off work sick ever. These countries would be better off keeping out bad drivers (or fat old bastards).
From a public health perspective, you’re not.
But you are more of a threat to their agenda.
“Infection rates are not soaring in the unvaccinated.” The issue now is vaccine injury and potential future injury.
There, fixed it for you!
Oops. Freudian slip. “Infection rates are soaring in the vaccinated”
The jabs “still have some worthwhile protective value against hospitalisation and death.”
Sorry but I disagree.
Do vaccines reduce hospitalisations and death?
“The vaccines do not reduce all-cause mortality, but rather produce genuine spikes in all-cause
mortality shortly after vaccination.”
Dr. Martin Neil is Professor in Computer Science and Statistics at Queen Mary, University of London. Dr. Clare Craig is a Diagnostic Pathologist. Dr. Norman Fenton is Professor of Risk Information Management at Queen Mary University of London. The paper is also authored by Jonathan Engler, Joshua Guetzkow, Scott Mclachlan, Jessica Rose, Dan Russell and Joel Smalley.
https://www.researchgate.net/publication/357778435_Official_mortality_data_for_England_suggest_systematic_miscategorisation_of_vaccine_status_and_uncertain_effectiveness_of_Covid-19_vaccination
Summarised here ……
https://dailysceptic.org/2022/01/21/do-covid-vaccines-reduce-all-cause-mortality-ons-data-give-us-no-reason-to-think-so/
The view that vaccines have a 90% effectiveness of reducing hospitalisation and death is flawed due to a number of reasons including the ‘healthy vaccinee’ effect.
A study published last year by the U.S. CDC found that vaccinated people were less likely to die of non-Covid causes, suggesting that they’re inherently healthier and/or more risk averse than unvaccinated people.
Those who are unvaccinated that end up in hospital and die could quite easily be due to the “unhealthy unvaccinated” effect.
Someone who is too ill or frail to have the jab is more likely to end up in hospital and the data shows that they were “unvaccinated” without any enquiry on their overall health status.
A rough sleeper or anyone else who is not on any health records who ends up in hospital is regarded as “unvaccinated”.
Someone who had the vaccination less than 14 days previously is regarded as unvaccinated in some studies. So if they end up in hospital due to Covid or vaccine induced health problems similar to Covid they are regarded as unvaccinated in the study even though it was the vaccine that caused it.
The vaccinated are also more likely to catch Covid within 14 days of their vaccine than the unvaccinated.
https://www.hartgroup.org/why-do-they-hide-what-happens-in-the-first-two-weeks-after-vaccination/
All these “healthy vaccinee”, “unhealthy unvaccinated” and vaccine induced Covid patients within 14 days of the jab (regarded as unvaccinated) in studies are skewing the figures making the jabs look a lot more effective than they really are (if they are effective at all).
We all know that the ONS has grossly underestimated the unjabbed population by the many articles on this website.
https://dailysceptic.org/2021/12/12/is-vaccine-effectiveness-against-death-mostly-a-statistical-illusion/
The people who gather the data for studies conveniently say that they are not allowed to show the unjabbed health status as it would contravene data protection laws.
I still haven’t seen any hard evidence that the jab is actually working.
https://dailysceptic.org/2022/01/21/more-evidence-for-the-healthy-vaccinee-effect/?fbclid=IwAR2ZVwNrlRXt0CPd0cfGfIb_UgIRgdXU7WENO7K0jYgFy_k3nfyCWeXJy4Y
Try reading the weekly vaccine surveillance report…The evidence is in there.
The “evidence” is flawed.
Leaving aside the detail as presented here, the fundamental issue arises from the astoundingly unethical approach that the whole ‘vaccine’ controversy has presented.
That a medicine is safe and necessary until proved to be not so is an absurd reversal of normal procedure and logic. Such evidence as presented here (and presented previously) simply shows (being generous) that the necessary assurance is far, far out of reach. The conclusions are obvious.
Lies Lies lies all the time
Rocketing Energy Prices Were Part Of The Plan All The Time
https://notalotofpeopleknowthat.wordpress.com/2022/01/29/rocketing-energy-prices-were-part-of-the-plan-all-the-time/
by Paul Homewood
Saturday 29th January 2pm
Wake up Wokingham Day
Meet outside Town Hall,
between Rose Inn & Costa
Wokingham RG40 1AP
Stand in the Park Sundays 10am make friends, ignore the madness & keep sane
Wokingham Howard Palmer Gardens Cockpit Path car park Sturges Rd RG40 2HD
Henley Mills Meadows (at the bandstand) Henley-on-Thames RG9 1DS
Telegram Group
http://t.me/astandintheparkbracknell
How much longer can all the Covid and ‘vaccine’ lies hold up – even with the support of the WEF ‘ army within’, the entire UK Government and censored Mainstream Media?
A table posted online today shows how the PCR test, on which the whole ‘scamdemic’ has been built, factors in 52 other virus pathogens that can cause a PCR test to show positive. Your positive test could therefore be for one of at least 53 viral traces.
This is apart from the fact that no PCR test of any kind can tell you whether you have a live infection or not.
Do PCR fanatics on here get that and what it tells us about the last two years of nightmare?
Time for a little ‘re-programming’ perhaps?
Given that I’ve so far avoided the sniffles and have yet to produce a positive test, I am proud to note that it’s not just one virus that I’m avoiding, but a whole raft of them!
I’m proud to say I haven’t had ‘the sniffles’ since 2018 when I got to grips with vitamin D intake and had my blood levels tested.
I had a very nasty respiratory illness in, er, 1977. The internet enabled me to diagnose it as ‘Russian flu’, which was going around then and killed about 700,000 worldwide.
No … I’d never heard of it before. Amazing contrast with today’s hypochondria.
Mad people with links to the US government are now engineering bird flu to be more dangerous
https://dilyana.bg/potential-pandemic-bird-flu-modified-to-be-more-dangerous-in-new-risky-nih-research/
So we all need to keep our immune systems in good nick, just in case.
SO you uses the internet in 1977, did you.
GO and find out when the internet became available….
I suspect he may have used the internet to refer back to 1977.
Surely it must be close to your bedtime?
“A table posted online today shows how the PCR test, on which the whole ‘scamdemic’ has been built, factors in 52 other virus pathogens that can cause a PCR test to show positive.”
Please post it on here because it doesn’t sound correct.
Making people believe that vaccinated people are safer to others is spreading misinformation. It is condemnable to force mRNA vaccinations and not to acknowledge natural immunity acquired from infection. mRNA vaccinations do not prevent infection or transmission of the virus. They only induce antibodies towards the spike protein that wane after three months and the cells which express the spike protein will be destroyed by the immune system causing myocarditis and damage to other organs that express the protein. mRNA injections can also cause menstrual disorders, thrombosis, and their long-term side effects are unknown. People who have acquired natural immunity from infection are much more protected than vaccinated people as naturally acquired immunity is targeted towards the whole virus and lasts for longer. Omicron doesn’t cause severe illness and thanks to its high transmissibility most people have already acquired long-lasting natural immunity from exposure which is going to lead to the end of the pandemic. Omicron is the best vaccine to obtain herd immunity and those who continue to enforce the unnecessary dangerous mRNA injections should be taken to court. If naturally acquired immunity is not acknowledged, none of the data released by the government can be trusted.
I take this analysis as providing further support to the propositions that (a) the “vaccines”, at best, provide only short-lived protection and (b) immunity acquired through infection is superior to that acquired through vaccination. The worry now is that evidence is also mounting that the vaccines may produce long-term detrimental effects on the immune system. This latter proposition requires objective and impartial investigation, and urgently. No doubt, though, there will be those who will be very keen to cover up what could prove to be the biggest scientific scandal in decades.
Pfizer et al won’t care. They’ve already banked the profits and are fully indemnified against any and all outrage caused by their products.
A good ‘business’ to be in…
If you look at the Pfizer share price since 1971, it’s almost constantly …
Up … up … up … and up again.
Most businesses could only dream of a situation where they need no insurance, they’re paid in advance for three years’ orders and the net margin is 50% or 100%.
You forgot to mention the added bonus that instead of having to pay people to join in their trial for a new drug, people are paying the drug company to participate in the trial…
And the other added bonus that as they were allowed to get away with shoving this sludge into hundreds of millions of people after only a 2-month trial and being allowed to unblind the control group, they have now been allowed to do the same with ‘tweaked’ boosters and their wonderful new pfizermectin.
But the analysis is a dishonest treatment of unadjusted data to reach a wrong conclusion.
How can you be fooled.
Dr John Campbell has an excellent video today quoting a BMJ article asking why the vaccine trail data has not been released for peer review. Even he, a relative main-streamer, invites us to be suspicious.
A distorting piece, based on unadjusted rates.
You could read the vaccine surveillance report in full to get the real conclusions.
So tell us. For let’s say a 40 year old. What is the probability of contracting covid and dying if the person is vaccinated and the probability of the person is not vaccinated.
Tell us.
Since (s)he won’t answer, I will.
Based on German statistics (for age group 35-59, so the number is likely still too high): the risk of dying from COVID-19 over a year within that age group has been ~0.02%. Of course this includes all pre-omicron deaths, so based on official estimates (likely also exaggerated), the actual risk of dying going forward is at most ~0.01%
For the 60-79 group the risk was 0.21%
For the 80+ group the risk was 1.37%
Of course death is not the only concern, surviving ICU does not exactly translate into great quality of life thereafter. So I’d say you can double these risks to account for that scenario.
And as for the mystical “long covid” the official estimates of affliction have gone down from 10% to 1% of all infected people.
Ok, according to your figures the risk is 0.01%. Is that jabbed or
And what is the risk for the other group?
0.01% without accounting for vaccination status. The difference in death risk between jabbed and unjabbed for a 40 year old will be maybe 2x.
Maybe?
How about you give me a properly sourced figure. Because you make very assertive comments on here, I’m assuming you have reliable figures that matter, not just vague words
What is the risk of a 40 year old dying of covid and the risk if he is not vaccinated. A properly sourced figure, not some vague estimate of yours.
For a healthy 40 year old, it’s zero.
For an unhealthy 40 year old, a fraction above zero.
But the intellectually challenged still believe they should be jabbed anyway, multiple times.
Your question does not address the fact that vaccine efficacy is well established as good and supported by real-life data.
You might as well ask my shoe size.
If you think you have evidence that proves otherwise, state it.
What is your shoe size?
I’d find that more interesting than anything else you’ve said.
Hat size might be more informative – very small, I’d guess!
Don’t just make the assertion. Give me the figures. Risk of dying of covid for a vaxed person and risk for an unvaxed.
Let’s see the figures.
Anyone who attempts to answer this question without mentioning the change in efficacy over time is giving a wrong number.
Most posts can pretty much be discarded, as they can only tell the story for some undeclared instant in time after some probably undeclared hotchpotch of varying doses of potentially different vaccines.
Well the tag team of rayc and rational seem to think they have a definite answer and berate anyone who suggests otherwise.
I’m asking them repeatedly to give me the key stats and I’m still waiting.
In the first graph, why does ‘efficacy’ fall off a cliff in the three age groups including all those aged 60 and over, at the exact same time despite being on an upward trend?
This data looks very manipulated to me.
Have we got a new boohoo free speech censor ?
In the old days you could cope with complaints by a disclaimer such as
Warning:
This forum may contain strong language. Please do not use it if you are easily offended.
The UK may now be so authoritarian that legally this no longer works.
It seems to me to be having the same effect that was recorded with animal MRNA vaccines years earlier by vets, and that illustrates why they were abandoned.
In the short run the animals appeared to have immunity. In the longer run they became more ill.
People knew that, and the attempts to put too much space between pets and humans was unhelpful, to say the least.
Fulham v Blackpool interrupted.
Another fan collapses in the stands.
What size was that crowd?
How many games were ongoing at the time?
What was the total crowd size?
What is the probability of a fan collapsing during that time frame in normal circumstances?
You can easily find out the first three questions yourself, although you appear to have asked the same question twice which is indicative of your mental capacity.
The fourth is more tricky, but I reckon the probability of an off- or on-field collapse before the vaccines was about the same as you posting a message worth reading (ie. almost zero).
Ah so you don’t understand probability, then.
You really should if you are going to attach significance to a particular event.
Don’t trouble yourself with what I do or don’t understand, focus on yourself.
Why not start with tying shoelaces?
So far 3 people seem to be please that someone collapsed.
Shocking…..Their thumbs say so!!!!!!!!!!
You’re now claiming to be able to interpret what people mean from an uptick.
Does your mama know you’re on the computer again?
Well they approve of your message and that’s the only information it conveys.
What else could they mean?
Well maybe it was useful information to them.
But you wouldn’t know anything about that, would you?
https://rumble.com/vtge32-tawny-buettner-rn-observed-a-10x-increase-in-the-rate-of-myocarditis-after-.html
She worked in the Cardiothoracic Intensive Care Unit (CTICU) of a major children’s hospital in San Diego, California for more than 12 years. Here’s her story about what she observed about myocarditis rates post vaccine. Yeah, it’s way worse than the rates caused by the virus.
I just noticed “rational” did not write a single response to my comments. Apparently it’s hard to argue when the official data defeat the case. And that is what we should be focusing on, utilizing the very official numbers concerning absolute risk to drive the pointlessness of the “measures” instead of inventing doubtful stories about killer/non-working vaccines. The key issue is not whether or not vaccines are working, the key issues is that they are simply not needed (for most).
Ah but that is not the subject that the original article attests to.
It wrongly states the efficacy is bad. Obviously you know this is wrong.
Efficacy is a relative risk issue.
Absolute risk is a different issue altogether. A distraction from the original subject?
I agree, the article is crap. But the absolute risk is what really matters.
Absolute risk is a factor for the rationale in the case of a particular age group being vaccinated. I agree.
But the authors on this site don’t focus on detailed aspects like this. They seek to give sweeping negative messages, based on garbage analysis of data. The readers here swallow it hook line and sinker and it becomes their belief. They have no knowledge that they have been fooled and worship those that fool them.
Laughable.
The fools are those who believed the propaganda about a 21st century Black Death and have allowed themselves to be injected several times with experimental gunk which hasn’t been properly tested in order to protect themselves against a disease that poses a trivial threat to most of them.
There simply is no benign explanation for the desire of governments to inject healthy people under 60 and their refusal to allow doctors to treat infected people with combinations of existing drugs.
Apart from wanting to save lives, which they have certainly done.
We have no idea of the long term consequences of the gunk injections, so you simply can’t honestly make that claim about the net effect. Unless you genuinely think that giving multiply-ill geriatrics a few more months of existence is by far the most important objective of health policy.
And as for the short term, jabbing children will very clearly result in more deaths than not jabbing them.
Oh dear, deluded as well.
Try 116 123 – I’ve heard it’s 24/7 nowadays, not surprising after the last two years
To be fair, those morons introducing all the restrictions based on vaccination status do not care about age groups either. So it’s basically a tit-for-tat, isn’t it?
https://childrenshealthdefense.org/defender/us-developing-vaccine-passport-system/?utm_source=salsa&eType=EmailBlastContent&eId=bcf8f93a-db44-4f1f-8e44-c3343bb314fc
U.S. Developing Vaccine Passport System Using Complex Web of Big Tech Partnerships
Just because the federal government isn’t directly developing a national vaccine database or vaccine passport system doesn’t mean such systems aren’t in the works — they are, and some of the Big Tech players involved have deep ties to multiple government agencies.
Police at Charing Cross police station stated to Piers Corbyn 27Jan (when he & his team came to serve info of CRIMES in 4 more vax centres) that the Met Police now have a new procedure to accept vax centre crime complaints. THEY ISSUED A CRIME INFO CARD BEARING THE CRIME NO 6029679/21 & the description “COVID 19 CRIME” (See pic). They took his details & said the (Hammersmith) CID in charge will contact directly those who report these crimes.
Piers said “This is a significant step forward. They are not now covering-up or being evasive about the Crime investigation & are streamlining collection of information through which we will report details of what we’ve found. If they don’t contact us reasonably fast we contact them (They provided details of the Hammersmith CID officer in charge).
Activists in other police regions across the UK now need to insist those regions also facilitate in a similar way the collection of covid 19 crime information to go into investigation 6029679/21″
https://t.me/s/Pierscorbyn
There did seem to be a change once the Hyland action was brought and the Rose action.
I suppose it was possible that our rulers believed their own propaganda and were not expecting the population to challenge their narrative.
Here is another link to the Hyland letter – very well written.
https://app.box.com/s/parw202pa5ykpn0rve9e1ir5brmqlkei
I don’t believe flu jabs are effective at all.
It used to make me sad to watch people who obviously couldn’t remember the last time they’d formed their own opinion about anything rush like prodded sheep, but more full of worry, to get “their” flu jabs every year. Morons. But trusting, not wicked or anything.
If only they had a clue what the rulers really think about the population.
The richest three or four people most of them have ever met one-to-one are almost certainly medics – and they don’t even know what medics (worth a couple of million quid, max) think of them.
There’s never been such a sh*t-brained epoch as this one.
https://trmlx.com/vaccine-injuries-in-the-dod-and-the-attempted-cover-up/
Attorney Tom Renz recently summarised the information from the US military equivalent of the civilian VAERS database.
Obviously, it confirmed what we know from VAERS.
Please share. The information doesn’t get any better than this.
https://t.me/s/robinmg
From Mike Yeadon
With Dr Wodarg, I wrote to warn the European Medicines Agency & the public Dec 1 2020 of this specific risk to female fertility.
Every normal news outlet censored us. The BBC turned its venom on me.
https://dryburgh.com/wp-content/uploads/2020/12/Wodarg_Yeadon_EMA_Petition_Pfizer_Trial_FINAL_01DEC2020_signed_with_Exhibits_geschwarzt.pdf
In 2021, I filed expert opinions in various legal cases. I don’t know where these got to.
If I can find it I will post it here. I think it proves intent. There are two major problems with the “vaccines”, one that applies to all of them (see petition) and a second, more shocking one applying only to the mRNA vaccines. These accumulate in ovaries. And they KNEW THEY WOULD. A 2012 paper confirms it. https://www.sciencedirect.com/science/article/abs/pii/S0168365912000892
Here, the authors aimed to prove I was wrong, but accidentally achieve the exact opposite
https://www.medrxiv.org/content/10.1101/2021.05.23.21257686v1
Here is my summary of vax adverse reactions for UK, Europe and USA, the latest Europe figures being released today.
Europe: nearly 13,000 dead and over 3.5m adverse reactions, of which half are serious.
USA: 22,607 deaths and over 1m adverse reactions.
UK: 1,970 deaths and 1.4m adverse reactions.
Pie charts are added to show the vax take up. Over half the UK appears to be boosted whereas about one quarter of the USA is boosted.
Personally, I am suspicious of the number of boosts in the UK. MHRA quote adverse reactions at a much lower rate for the booster. I suspect the booster total is that delivered to jab stations rather than those actually administered.
I have gathered a lot more data, but this will do for the moment.
According to the UK Column referencing EudraVigilance, there were over 32,000 deaths recorded by early as December, 21 in Europe:
https://www.ukcolumn.org/community/forums/topic/yellow-card-vs-eudravigilance-vs-vaers-2/
As you see in the table, the total deaths totted up from adverse reactions is 38,993. Most people quote that number. But there are several adverse reactions to each death – currently averaging about 3 as quoted in the table and explained underneath. See what EMA say here.
The monthly Vaccine Safety Updates for each ‘vaccine’ give a total number of adverse reactions and total number of deaths. That provides a factor that I use to approximate the real number of deaths. It is different for each vaccine – markedly so. The last reports dated 20 Jan show Pfizer 1.99, AstraZeneca 2.95, Moderna 9.83, Janssen 7.21. The value of 3.00 that I quote is averaged, just as an indicator (although each vaccine’s results are factored by their individual value).
I have actually informed UKcolumn about this – particularly after Wednesday’s programme when they referred to Yellow Cards possibly having the same issue. I have not had a reply.
Thank you for the explanation – please keep up the good work!
A bit more data here, from which my summary was taken.
What is the expected mortality of each of these populations, in a 1 week period?
That would give you a background mortality to compare your claimed vaccine related deaths.
Until you do that your collection of numbers is entirely meaningless.
Even an anti-vaxxer should admit that people are not immortal. 1% die each year!
S0 take USA. 330e6 population x 1% / 52 = 31,730 is the expected mortality per week.
Lets say 50% got vaccinated twice in a year. so expected number of deaths within 1 week of a vaccination is….. 31,730. That’s a bigger number than you claim.
Oh…. it looks like you don’t have a case….
Fewer people died in Norway in 2020 than the average of the previous 5 years.
So there’s no health emergency.
In the UK total deaths – adjusted for population size and age – were lower than the average of the first decade of this century.
So there’s no health emergency
330e6 population x 1% / 52 = 31,730
Oh dear…looks like you’ll struggle to get that GCSE in a few years.
I am sorry that you are unable (or unwilling) to see a meaning.
The rate of people run over by a bus each year is far less that the mortality rate, but that does not mean that we turn a blind eye to them. For if they reach even a fraction of that, an investigation would be held.
Adverse reports are submited after drugs and jabs when there is a suspicion that they have caused them. Normally, jabs are usually pulled for investigation if a small two-digit total is reached. These jabs have reports of 10s of 1,000s of deaths – yet, instead of being pulled, they are pushed.
Indeed – unintelligent people (or trolls!) assume that the vaccine adverse reactions sites are supposed to record all cases! In fact, they are set up as an early warning system – as such, they have actually worked very well. It’s just that the authorities around the world have decided to ignore the clear warnings!
The question that needs to be asked is: why?
Interesting that the proportion of deaths per population seems similar for UK and EU.But the difference per population between UK and US is different, twice as many deaths in the US as in the UK.
Yes. All three databases (or two databases and some Acrobat files) have significant flaws and are most likely under-reported. But there has been enough data to stop the jab programme for the last 10 months. And there is enough rope to hang the culprits several times over (without giving the blighters a PCR test).
My triple jabbed neighbours in their 90s currently have covid, they have been self isolating for the 2 years now and barely leave the house and their career is jabbed. They are ill but but at home, the man is 96 and not in great health anyway and won’t make it beyond this year. At the end of the day whether the jab has made any difference or not he has wasted close to 100% of his last days shut at home afraid of seeing anyone. What is the point of living like that?
You get to a certain age and you die, so its nonsense going on about lives saved when the average age of death with covid is over 80, you might kick the can down the road for a few months for some people, but it ruins the quality of life for everyone else in the world. I always thought Doctors were meant to be realistic about quality of life and death. Now ‘experts’ talk like by saving someone from covid they are going to be immortal.
Shouldn’t you consider that most of the unvaccinated have been previously infected? It’s much more likely that this data results from the increasing difference in natural immunity between vaccinated and unvaccinated and that vaccination does retain some efficacy in the never infected. Let’s not be like the lockdown fanatics and jump to whatever is the most convenient conclusion for our pre-existing beliefs.
The data show there’s no reason for restrictions based on vaccine status or for that matter any restrictions at all. Any elderly or severely immune compromised person that hasn’t either been infected already or vaccinated should be advised to get vaccinated, but only if they freely consent after being informed of the risks of side effects in their age group. Anyone that has symptoms of a respiratory virus should try to avoid prolonged contact with elderly relatives and as a courtesy to others might want to wear a mask when in shops or on public transport (fully acknowledging that there is no high quality data that this works).
“as a courtesy to others might want to wear a mask when in shops or on public transport (fully acknowledging that there is no high quality data that this works).”
I might not want to wear a mask actually, because I am a horrible selfish person who doesn’t prioritise other people’s wellbeing over his own. Alternatively, not wearing a mask is an act of altruism because I’m not pandering to people self-destructive delusions that there is a deadly pandemic on the go and a mask will save them. The idea that we should be concerned with keeping strangers safe from viruses over which we have no control is pernicious.
Hear hear!!!
https://odysee.com/@spearhead4truth:e/Nanotech-discovery-280122:9
Intelligent discussion on recent findings on the vaxxes.
Nanotech found in Pfizer jab by New Zealand lab. Sue Grey Co-leader of Outdoors and Freedom Party and Dr Matt Shelton report findings to Parliament’s Health Select Committee.
http://www.orwell.city has been publishing similar work from Spain, since last year, as have German pathologists
Sadly, I suspect this will be used to terrorise two-dosers into getting a third.
Then when the numbers for that plummet as well, a fourth.
And on and on and on, faster and faster and faster, chasing the dragon of immunity without end until either the coofs or the coof-shots get you.
Just stop it stop it please!
Looks increasingly like Dr. Mike Yeadon is correct: the main reason for scaring people in to joining the “vaccination” experiment is population control. Mother trucking bastiges!
The very negative vaccine effectiveness of double vaccination relative to triple vaccination is almost certainly an artefact of removing the infected from the triple injected treatment cohort and returning them to the double injected cohort during the 28 day period after treatment. I discuss it here: https://richardlyon.substack.com/p/the-vaccine-effectiveness-trick
I am one of those who, about 3 weeks after taking the first AZ vaccine, got the Delta variant and now, about 3 weeks after taking the booster (having been emotionally blackmailed into it by family), got Omicron. It was little more than a mild cold for about 2 days. I have now set down the law, that I am taking no more of these.
Why do I get the impression that it doesn’t matter in the slightest that this ´medical treatment’ a) DOESN’T work and b) might be detrimental. It’s the same with masks – it seems to be just something that people seem willing to accept either because they don’t have the guts/time/energy to object. When did the ease of going on holiday become more important than how we loved our lives the other 50 weeks of the year? When did it become too much effort to stand up for something you really believe in – in this case bodily autonomy and freedom.
After 2 years of this nonsense I am afraid I have lost respect for most people. The creeping fascism in Europe could not have happened if ordinary people had objected from the very beginning. Thank God for the Canadians!
Now in Australia, and in many other countries. The MSM is ignoring, but it’s easily found on Youtube.
So can we assume that the UNjabbed, once they’ve had ”it”, having uncompromised immune systems, won’t get reinfected? And this is why the jabbed are being reinfected at such a rate?