
How do psychologists get data to test their theories? The traditional method was to recruit a sample of undergraduate students from their university. While this was very convenient, it had one obvious disadvantage: undergraduate students aren’t necessarily representative of the population – let alone all humanity.
In recent years, therefore, psychologists have turned to online survey platforms – the most popular of which is Amazon’s Mechanical Turk. How does it work? Individuals sign up to be ‘MTurk workers’ and can then be recruited to participate in academic studies. They are paid a small fee each time they participate in one. Specifically, they are paid a minimum of $0.01 per ‘assignment’, with a typical study involving many ‘assignments’.
MTurk has become extremely popular among psychologists and other academics. Over 40% of the articles in some journals are based on MTurk data, so we’re talking about thousands of studies. The problem is that most of these studies may be flawed.
Why?
A growing body of evidence indicates that MTurk data is of very low quality, due to the high percentage of MTurk workers who are careless responders. By ‘high percentage’ I mean upwards of 75%. Careless responders may click options randomly, or they may engage in what’s called ‘straightlining’ where they click the first option that appears for each successive question. Both types of responding yield data that is worthless.
In a new preprint, Cameron Kay provides a particularly vivid illustration of the problems with MTurk. His methodology was simple: he recruited a sample of MTurk workers and gave them 27 ‘semantic antonyms’. These are pairs of items that ought to yield opposite answers: for example, “I am an extravert” and “I am an introvert”, or “I talk a lot” and “I rarely talk”.
If most respondents are paying attention and taking the study seriously, the pairs of items will be negatively correlated. There’ll be a tendency for people who agree with “I am an extravert” to disagree with “I am an introvert”. By contrast, if most respondents are straightlining, the pairs of items will be positively correlated. And if most respondents are clicking randomly, the pairs of items won’t be correlated at all.
What did Kay find? 26 out of 27 pairs of items were positively correlated. In other words, there was a tendency for respondents who agreed with “I am an extravert” to agree with “I am an introvert” – complete nonsense. This is shown in the chart below.
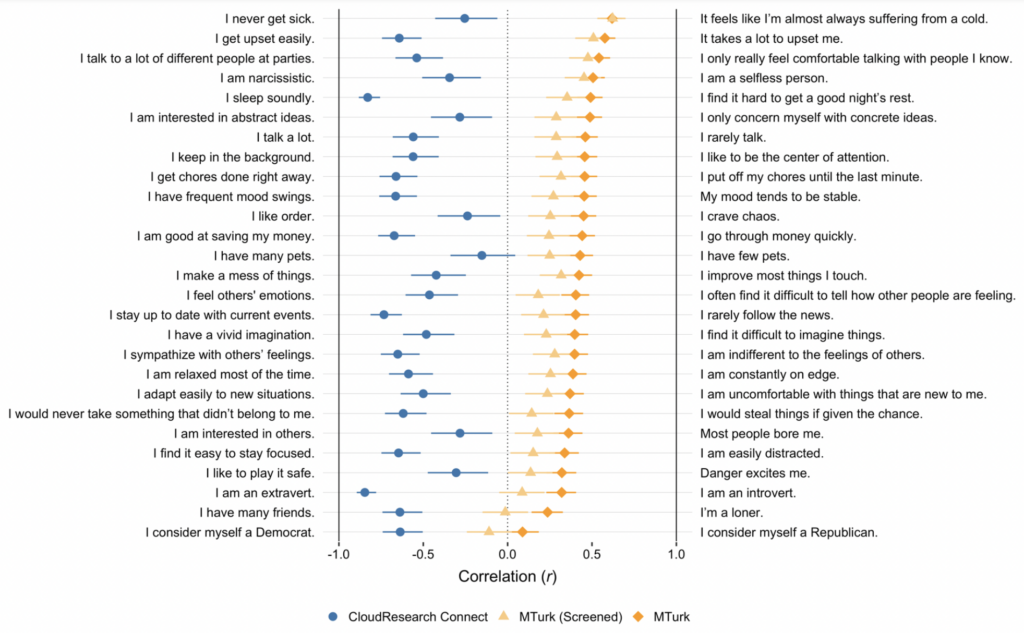
To see whether the data could be salvaged, Kay re-ran the numbers after excluding 47% of respondents who failed one or more checks for careless responding: they answered faster than 2 seconds per item; they responded the same way to half the items in a row; and/or they answered incorrectly to items where the answer was given (e.g., ‘choose disagree’). Even after excluding nearly half the respondents, 24 out of 27 items were still significantly positively correlated – as shown in the light-orange bars above.
Interestingly, when he gave the same semantic antonyms to a sample recruited from CloudResearch Connect, another online survey platform, they had the expected negative correlations. These are shown in the blue bars above. So the good news is that the problem of careless responding appears to be specific to MTurk, rather than one that afflicts all online survey platforms.
CloudResearch Connect workers are typically paid more than their counterparts on MTurk and hence may be less inclined to respond carelessly (although in Kay’s study, the two samples were both paid the equivalent of $8 per hour).
There has been much talk of a ‘replication crisis’ in psychology and other disciplines, which has been attributed to a combination of publication bias and questionable research practices. We may soon hear about a ‘second replication crisis’, stemming from the overreliance on MTurk data.












To join in with the discussion please make a donation to The Daily Sceptic.
Profanity and abuse will be removed and may lead to a permanent ban.
Well that’s a surprise …. said no-one. You’re asking students to take their time on a study which pays the square root of FA, and expect them to take time and care over this? They want to grab a bit of cash asap, so they can get back to their avocados, box setting TV shows and protests on climate.
Do psychologists any idea of human nature?
To answer the question of the article – do bears usually shit in the woods?
Psycho babble. Another non profession and non industry. The ugly brother of virology and a gaggle of other non-sciences one could mention.
Interesting. I’ve used MTurk in the past, and I remember having to be careful to weed out “fake” user input of the sort discussed (less of a problem in the experiment I ran, which was an interactive game). But to be fair to MTurk, that’s as much of a software “security” issue (studies are actually performed on the experimenter’s own website/platform), akin to bots in video games. But psychologists don’t tend to be good coders. Will check out CloudResearch Connect.
I am not on Twitter (X) but according to Bev on GBN Mark Dolan has praised the vaccine rollout on a Tweet, maybe in connection with the contaminated blood scandal. If that is correct he really is a ‘Cos Play Freedom fighter!’
It’s not correct. He was being ironic:
“The infected blood scandal is a profound moment of national shame.
Government, the NHS and the civil service failed thousands of tragic victims.
Luckily, things have changed and the COVID-19 vaccine rollout was ethical, proportionate and did no harm”
https://x.com/mrmarkdolan/status/1792569180585157060
Psychology is not a science! Science exists to study nature partly in order to establish a rational basis for decision making. “without a standard there is no basis for rational desicion making.” Joseph moran
STEM science have standards, the laws of maths and physics, the periodic table, the classification of species. Psychology is the study of human behaviour. Show me a standard human being, anyone?
In 1973 Andreski (professor of sociology at Reading) published a book called ‘Social Sciences as Sorcery’ His bugbear was the bogus use of mathematics to make a study seem scientific. Well worth a read if you can still find a copy
“Are a Large Percentage of Recent Psychology Studies Flawed?”
Replace ‘A Large Percentage of’ with ‘All’ and delete ‘Recent’;
Then the answer to this corrected question is ‘of course’.
Human beings have both free will and an eternal soul (two sides of the same coin) and therefore their thoughts and behaviour can’t be either examined or controlled in a deterministic / empirical manner (unlike purely material phenomenon such as the conservation of energy or gravity).
In other words psychology (and its chemical enforcement adjunct known as psychiatry) is a pseudo science – and an incredibly malign one at that.