

Findings reported by ecologists are hugely influential in policy debates over agriculture, pollution, climate change, conservation and biodiversity. But can we trust them? A recent paper suggests that some scepticism is in order.
Kaitlin Kimmel and colleagues set out to examine the prevalence of “questionable research practices” in the field of ecology. QRPs, as they are known, include things like not making your data and code available for other researchers to check. They also include more subtle things like selectively reporting results, tweaking the analysis until you get a significant result (‘p-hacking’) and forming hypotheses after the results are known (‘HARKing’).
It is not only researchers who engage in QRPs. Journal editors often reject papers with null or weak findings because they believe such findings will be less impactful and less interesting to readers. This leads to an ‘exaggeration bias’, whereby the average effect size appears larger than it really is because null or weak findings are not represented in the published literature.
For example, suppose 10 studies are done, five of which find weak effects and five of which find strong effects. If only the latter five end up getting published, the published literature will exaggerate the effect size in question. Such variability in results is common when sample sizes are small (when studies are ‘under-powered’, to use the technical jargon).
Kimmel and colleagues obtained relevant statistics from 354 articles that were published in five top ecology journals between 2018 and 2020. In one part of their analysis, they looked at the distribution of t-statistics reported by the articles in their sample. The t-statistic is something you calculate, which tells you how likely your results would be under the assumption of no effect. If it is large, that indicates your results would be unlikely under this assumption and hence that there probably is an effect.
What’s important is that, by convention, t-statistics greater than 1.96 are deemed significant whereas those below 1.96 are deemed non-significant. So if researchers were selectively reporting their results, you’d expect to see a discontinuity in the distribution, with fewer than expected just below 1.96 and more than expected just above 1.96. And this is just what Kimmel and colleagues found!
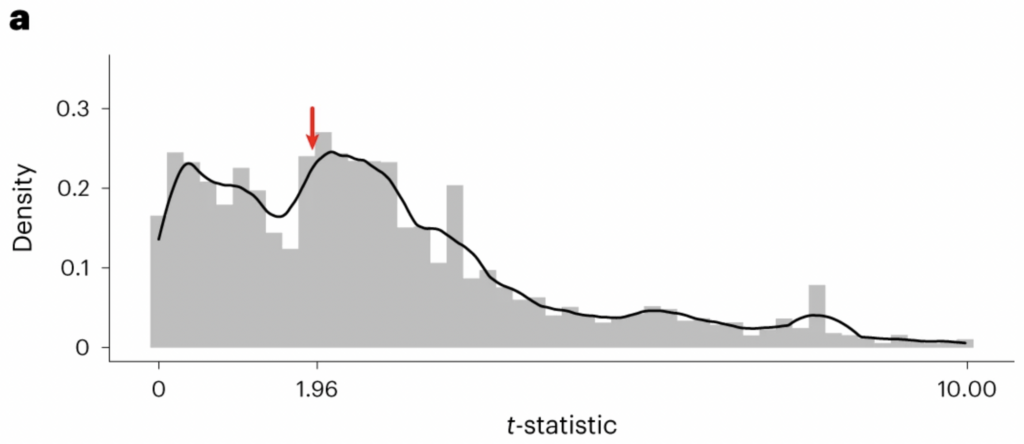
As you can see, there’s a dip in the distribution just below 1.96 and spike just above it. Which can only be explained by some combination of HARKing, p-hacking and selective reporting of results. In fact, Kimmel and colleagues found additional evidence for selective reporting. When they examined the distribution of t-statistics from articles’ appendices, there was no discontinuity around 1.96 – as shown below.
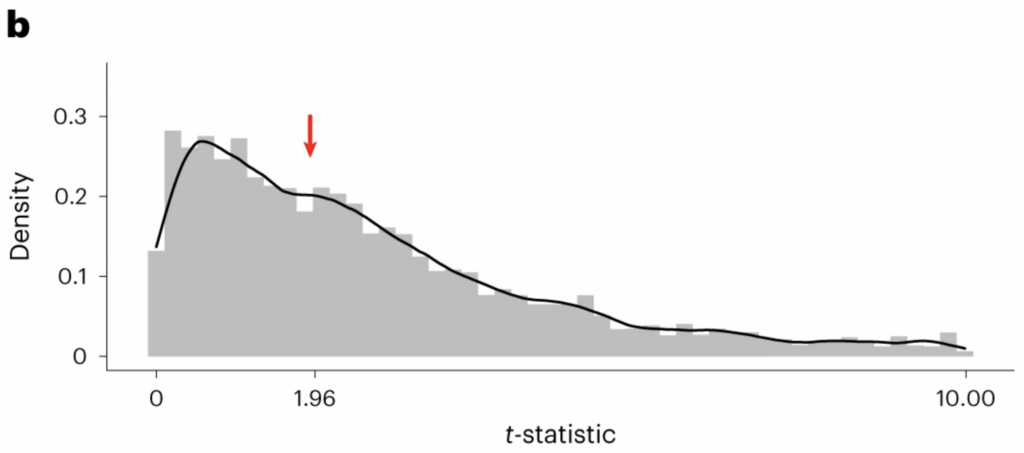
Which means that researchers were accurately reporting results in their appendices but selectively reporting results in their main texts. (This make sense, given that articles are typically be judged on the basis of their main findings, rather than any supplementary results.)
Kimmel and colleagues also found evidence for exaggeration bias in the ecology literature. In addition, they found that although data were available for 80% of the articles in their sample, code was available for less than 20%. Which means that the vast majority of articles’ results could not be reproduced without rewriting the code from scratch.
“The published effect sizes in ecology journals,” the authors write, “exaggerate the importance of the ecological relationships that they aim to quantify”. This, in turn, “hinders the ability of empirical ecology to reliably contribute to science, policy, and management”.
The paper doesn’t identify which specific “ecological relationships” are most exaggerated, nor which areas of the field are most affected, but it does offer general grounds for scepticism. Keep this in mind the next time you’re reading the science section.









To join in with the discussion please make a donation to The Daily Sceptic.
Profanity and abuse will be removed and may lead to a permanent ban.