
Out of the Darkness and Into the Murk
This article takes a look at the quality of the software behind Professor Neil Ferguson of Imperial College London’s infamous “Report 9“. My colleague Derek Winton has already analysed the software methods; I will consider the quality of the development process.
Firstly, you’ll want to inspect my bona fides. I have an MSc in engineering and a lifetime in engineering and IT, most of which has been spent in software and systems testing and is now mainly in data architecture. I have worked as a freelance consultant in about 40 companies including banks, manufacturers and the ONS. The engineer in me really doesn’t like sloppiness or amateurism in software.
We’re going to look at the code that can be found here. This is a public repository containing all the code needed to re-run Prof. Ferguson’s notorious simulations – feel free to download it all and try it yourself. The code will build and run on Windows or Ubuntu Linux and may run on other POSIX-compliant platforms. Endless fun for all the family.
The repository is hosted (stored and managed) in GitHub, which is a widely-used professional tool, probably the world’s most widely-used tool for this purpose. The code and supporting documentation exist in multiple versions so that a full history of development is preserved. The runnable code is built directly from this repository so a very tight control is exercised over the delivered program. So far, so very good industrial practice. The code itself has been investigated several times, so I’ll ignore that and demonstrate some interesting aspects of its metadata.
Firstly, the repository was created on March 22nd 2020, one day before the first – disastrous – lockdown in England was applied. There was a considerable amount of development activity from mid-April until mid-July (see below) and then a decreasing level of activity until by the end of December 2020 development had practically ceased. In February 2021, however, work restarted and peaked in April, falling away again quite quickly. Since then it has been almost entirely quiescent and appears to have been totally silent since July 2021. The repository was substantially complete by mid-June 2020 and almost all activity since then has been in editing existing code.
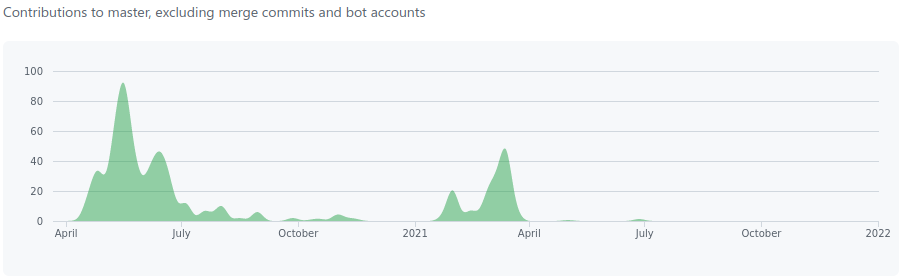
As “Report 9” was published on March 16th 2020, and the criticism of it started almost immediately, it’s very tempting to suggest that the initial period of activity matches the panic to generate something presentable enough to show to the public to support the Government’s initial lockdown. The second campaign of work may be revisions to tune the code to better match the effects of the vaccination programme.
Twenty-two people have contributed to the codebase, including the aforementioned Derek Winton. The lead developer seems to be Wes Hinsley, who is a researcher at ICL. He has an MSc in Computer Engineering and a doctorate in Computing and Earth Sciences, so would appear to be well-qualified to manage the development of something such as this.
This repository is unusual in that it appears to contain every aspect of the software development life cycle – designs and specifications (such as they are), code, tests, test results and defect reports. This is symptomatic of a casual approach to software development management and is often seen in small companies or in unofficial projects in large companies.
However, it does mean that we can gain a good understanding of the real state of the project, which is that it is not as good as I would have hoped it would be for such an influential system. We can read a lot from the “issues” that have been recorded in GitHub.
Issues are things such as test defects, new features, comments and pretty much anything else that people want to be recorded. They are written by engineers for other engineers, so generally are honest and contain good information: these appear to be very much of that ilk. Engineers usually cannot lie; that is why we are rarely ever allowed to meet potential customers before any sale happens. We can trust these comments.
The first issue was added on April 1st 2020 and the last of the 487 so far (two have been deleted) was added on May 6th 2021. Out of the 485 remaining, only two have been labelled as “bugs”, i.e., code faults, which is an unusually low number for this size of a codebase. However, only two are labelled as “enhancements” and in fact a total of 473 (98%) have no label at all, making any analysis practically impossible. This is not good practice.
Only one issue is labelled as “documentation” as there is a branch (folder) specifically for system documentation. The provided documentation looks to be reasonably well laid out but is all marked as WIP – Work in Progress. This means that there is no signed-off design for the software that has been central to the rapid shutdown and slow destruction of our society.
At the time of writing – May 2022 – there are still 33 issues outstanding. They have been open for months and there is no sign that any of these is being worked on. The presence of open issues is not in itself a problem. Most software is deployed with known issues, but these are always reported in the software release notes, along with descriptions of the appropriate mitigations. There do not appear to be any release notes for any version of this software.
One encouraging aspect of this repository is the presence of branches containing tests, as software is frequently built and launched without adequate testing. However, these are what we in the trade call ‘unit’ tests – used by developers to check their own work as it is written, compiled and built. There are no functional tests, and no high-level test plans nor any test strategy. There is no way for a disinterested tester to make any adequate assessment of the quality of this software. This is extremely poor practice.
This lack of testing resource is understandable when we realise that what we have in this GitHub is not the code that was used to produce Neil Ferguson’s “Report 9”: it is a reduced, reorganised and sanitised version of it. It appears that the state of the original 13,000-plus line monolith was so embarrassing that Ferguson’s financial backer, the Bill and Melinda Gates Foundation, rushed to save face by funding this GitHub (owned by Microsoft) and providing the expert resource necessary to carry out the conversion to something that at least looks like and performs like modern industrial software.
One side-effect of this conversion, though, has been the admission and indeed the highlighting, of a major problem that plagued the original system and made it so unstable as to be unsafe to use, although it was often denied.
We Knew It Was Wrong, Now We Know Why
One of the major controversies that almost immediately surrounded Neil Ferguson’s modelling software once the sanitised version of the code was released to the public gaze via GitHub was that it didn’t always produce the same results given the same inputs. In IT-speak, the code was said to be non-deterministic when it should have been deterministic. This was widely bruited as an example of poor code quality, and used as a reason why the simulations that resulted could not be trusted.
The Ferguson team replied with statements that the code was not intended to be deterministic, it was stochastic and was expected to produce different results every time.
Rather bizarrely, both sides of the argument were correct. The comments recorded as issues in GitHub explain why.
Before we go any further I need to explain a couple of computing terms – deterministic and stochastic.
Deterministic software will always provide the same outputs given the same inputs. This is what most people understand software to do – just provide a way of automating repetitive processes.
Stochastic software is used for statistical modelling and is designed to run many times, looping round with gradually changing parameters to calculate the evolution of a disease, or a population, or radioactive decay, or some other progressive process. This type of program is designed with randomised variables, either programmed at the start (exogenous) or altered on the fly by the results of actual runs (endogenous) and is intended to be run many times so that the results of many runs can be averaged after outlying results have been removed. Although detailed results will differ, all runs should provide results within a particular envelope that will be increasingly better defined as research progresses.
This is a well-known modelling technique, sometimes known as Monte Carlo simulation – I’ve programmed it myself many years ago, and have tested similar systems within ONS. Stochastic simulation can be very powerful, but the nature of the iterative process can compound small errors greatly, so it is difficult to get right. Testing this kind of program is a specialist matter, as outputs cannot be predicted beforehand.
To explain the initial problem fully: people who downloaded the code from GitHub and ran it more than once would find that the outputs from the simulation runs would be different every time, sometimes hugely so, with no apparent reason. Numbers of infections and deaths calculated could be different depending on the type of computer, operating system, amount of RAM, or even the time of day.
This led to a lot of immediate criticism that the software was non-deterministic. As mentioned above, the Ferguson team retorted that it was meant to be stochastic, not deterministic, and in the GitHub repository we find the following supporting notes (screenshot below). The third one is important.
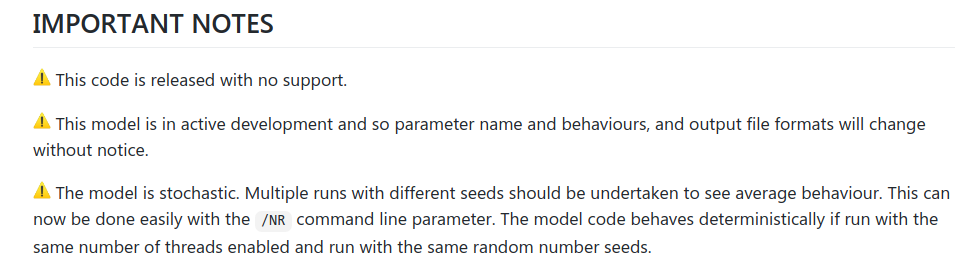
So it’s meant to be stochastic, not deterministic. That would be as expected for statistical modelling software. The problem is that, when we look at what the honest, upstanding engineers have written in their notes to themselves (screenshot below), we find this noted as Issue 161:
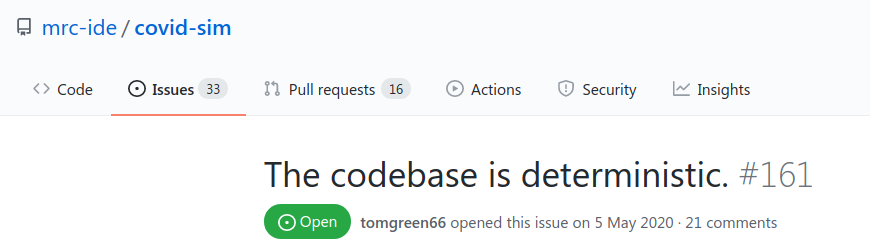
Of the 487 issues originally opened against this project, only one is considered important enough to be pinned to the top of the list. As you can see, it directly contradicts the assertions from the Ferguson team. That’s why engineers aren’t allowed to talk to customers or the public.
Reading the detail in Issue 161 reveals why the system is simultaneously deterministic and stochastic – a sort of Schrödinger’s model of mass destruction.
It turns out that the software essentially comprises two distinct parts: there is a setup (deterministic) stage that sets all of the exogenous variables and initialises data sets; and the second (stochastic) part that actually performs the projection runs and is the main point of the system.
The setup stage is intended to be – and in fact must be from a functional point of view – entirely deterministic. For the stochastic runs to be properly comparable, their initial exogenous variables must all be exactly the same every time the stochastic stage is invoked. Unfortunately, Issue 161 records that this was not the case, and explains why not.
It’s a bit technical, but it involves what we in the trade call ‘race conditions’. These can occur when several processes are run simultaneously by multi-threaded code and ‘race’ to their conclusions. Used properly, this technique can make programs run very quickly and efficiently by utilising all processor cores. Used wrongly, it can lead to unstable programs, and this is what has happened in this case. In the trade we would say that this software is not ‘thread safe’.
Race conditions happen when processes do not always take a consistently predicted amount of time to complete and terminate in unexpected sequences. There are many reasons why this may happen. This can mean that a new process can start before all of its own expected initial conditions are set correctly. In turn this makes the performance of the new process unpredictable, and this unpredictability can compound over perhaps many thousands of processes that will run before a program finishes. Where undetected race conditions occur, there may be many thousands of possible results, all apparently correct.
They may be due to differences in processor types or local libraries. There are many possible causes. Whatever the cause in this instance, every time this code was run before May 6th 2020 (and probably up to about 17th May 2020 when Issue 272 was opened and the code simplified) the result was unpredictable. That was why the results differed depending on where it was run and by whom, not because of its stochastic nature.
In itself, this problem is very bad and is the result of poor programming practice. It is now fixed so shouldn’t happen again. But, as we shall see, we cannot depend even on this new code for reliable outputs.
Where It All Came From and Why It Doesn’t Work
I have had the opportunity to work with a multitude of very capable professionals over the quarter century or so that I have been a freelance consultant, in many different spheres. Very capable in their own specialism, that is; when it came to writing code, they were nearly all disasters. Coding well is much harder than it seems. Despite what many people think, the development of software for high-consequence applications is best left not to subject experts, but to professional software developers.
I have no information as to the genesis of Professor Ferguson’s modelling code, but I’m willing to bet it followed a route similar to one that I have seen many times. Remember that this codebase first saw silicon many years ago, so came from a simpler, more innocent age.
- Clever Cookie (CC) has a difficult problem to solve
- CC has a new computer and a little bit of programming knowledge
- CC writes a program (eventually) to successfully solve a particular problem
- CC finds another problem similar to, but not identical to, the previous one
- CC hacks the existing code to cope with the new conditions
- CC modifies the program (eventually) to successfully solve the new problem
- GOTO 4
And so the cycle continues and the code grows over time. It may never stop growing until the CC retires or dies. Once either of those events happens, the code will probably also be retired, never to run again, because nobody else will understand it. Pet projects are very often matters of jealous secrecy and it is possible that no-one has ever even seen it run. There will be no documentation, no user guides, no designs, probably not even anything to say what it’s meant to do. There may be some internal comments in the code but they will no longer be reliable as they will have been written for an earlier iteration. There are almost certainly no earlier local versions of the code and it may only exist on a single computer. Worse than that, it may exist in several places, all subtly different in unknown ways. There would be no test reports to verify the quality of any of its manifestations and check for regression errors.
If Professor Ferguson had been suddenly removed from Imperial College in January 2020, I am confident that the situation described above would have obtained. The reason why I am confident about this is that none of the collateral that should accompany any development project has been lodged in the GitHub repository. Nothing at all. No designs, no functional or technical descriptions, no test strategy, test plans, test results, defect records or rectification reports; no release notes.
To all intents and purposes, there is no apparent meaningful design documentation and I know from talking with one of the contributors to the project that this is indeed the case. Despite this, Wes Hinsley and his team have managed to convert the original code (still never seen in public) into something that looks and behaves like industrial-quality bespoke software. How could have they managed to do this?
Well, they did have the undoubted advantage of easy access to the originator, ‘designer’ and developer of the software himself, Professor Neil Ferguson. In fact, given the rapid pace of the initial development, I suspect he was on hand pretty much all of the time. However, development would not have followed anything vaguely recognisable as sound industrial practice. How could it, with no design or test documentation?
I have been in this position several times, when clients have asked me to test software that replaces an existing system. On asking for the functional specifications, I am usually told that they don’t exist but “the developers have used the existing system, just check the outputs against that”. At that point I ask for the test reports for the existing system. When told that they don’t exist, I explain that there is no point in using a gauge of unknown quality and the conversation ends, sometimes in an embarrassed silence. I then have to spend a lot of time working out what the developers thought they were doing and generating specifications that can be agreed and tested.
What follows is only my surmise, but it’s one based on years of experience. I think that Wes was asked to help rescue Neil’s reputation in order to justify Boris’s capitulation to Neil’s apocalyptic prognostications. Neil couldn’t produce any designs so he and Wes (and the team) built some software using 21st century methods that would replicate the software that had produced the “Report 9” outputs.
As the remarkably swift development progressed, constant checks would be made against the original system, either comparing outputs against previous results or based on concurrent running with similar input parameters. The main part of the development appears to have been largely complete by the third week of June 2020.
The reason that I describe this as remarkably swift is that it is a complicated system with many inputs and variables, and for the first six weeks or so it would not have been at all possible to test it with any confidence at all in its outputs. In fact, for probably the first two months or so the outputs would probably have have been so variable as to be entirely meaningless.
Remember that it wasn’t until May 5th 2020 – six weeks after this conversion project started – that it was realised that the first (setup) part of the code didn’t work correctly at all so the second (iterative) part simply could not be relied on. Rectifying the first part would at least allow that part to be reliably tested, and although there is no evidence of this having actually happened, we can probably have some confidence that the setup routine produced reasonably consistent sets of exogenous variables from about May 12th 2020 onwards.
A stable setup routine would at least mean that the stochastic part of the software would start from the same point every time and its outputs should have been more consistent. Consistency across multiple runs, though, is no guarantee of quality in itself and the only external gauge would likely have been Professor Ferguson’s own estimations of their accuracy.
However, his own estimations will have been conditioned by his long experience with the original code and we cannot have much confidence in that, especially given its published outputs in every national or international emergency since Britain’s foot and mouth outbreak in 2001. These were nearly always wrong by one or two orders of magnitude (factors of 10 to 100 times). If the new system produced much the same outputs as the old system, it was also almost certainly wrong but we will probably never know, because that original code is still secret.
The IT industry gets away with a lack of rigour that would kill almost any other industry while at the same time often exerting influence far beyond its worth. This is because most people do not understand its voodoo and will simply believe the summations of plausible practitioners in preference to questioning them and perhaps appearing ignorant. Politicians do not enjoy appearing ignorant, however ignorant they may be.
In the next section we are going to go into some detail about the deficiencies of amateur code development and the difficulties of testing stochastic software. It will explain why clever people nearly always write bad software and why testing stochastic software is so hard to do that very few people do it properly. It’s a bit geeky so if you are not a real nerd, please feel free to skip on to the next section.
Gentlemen and Players
You’ll remember from above that our Clever Cookie (CC) had decided to automate some tricky problems by writing some clever code, using this procedure.
- CC has a difficult problem to solve
- CC has a new computer and a little bit of programming knowledge
- CC writes a program (eventually) to successfully solve a particular problem
- CC finds another problem similar to, but not identical to, the previous one
- CC hacks the existing code to cope with the new conditions
- CC modifies the program (eventually) to successfully solve the new problem
- GOTO 4
The very first code may well have been written at the kitchen table – it often is – and brought into work as a semi-complete prototype. More time is spent on it and eventually something that everyone agrees is useful is produced. The dominant development process is trial and error – lots of both – but something will run and produce an output.
For the first project there may well be some checking of the outputs against expected values and, as long as these match often enough and closely enough, the code will be pronounced a success and placed into production use.
When the second project comes along, the code will be hacked (an honourable term amongst developers) to serve its new purposes. The same trial and error will eventually yield a working system and it will be placed into production for the second purpose. It will also probably remain in production for its original purpose as well.
Now, during the development of the second project it is possible, although unlikely, that the outputs relevant to the first project are maintained. This would be done by running the same test routines as during the first development alongside the test routines for the second. When the third project comes along, the first and second test suites should be run alongside the new ones for the third.
This is called ‘regression testing’ and continues as long as any part of the code is under any kind of active development. Its purpose is to ensure that changes or additions to any part of the code do not adversely effect any existing part. Amateurs very rarely, if ever, perform this kind of testing and may not even understand the necessity for it.
If an error creeps into any part of the code that is shared between projects, that error will cascade into all affected projects and, if regression testing is not done, will exist in the codebase invisibly. As more and more projects are added, the effects of the errors may spread.
The very worst possibility is that the errors in the early projects are small, but grow slowly over time as code is added. If this happens (and it can!) the wrong results will not be noticed because there is no external gauge, and the outputs may drift very far from the correct values over time.
And this is just for deterministic software, the kind where you can predict exactly what should come out as long as you know what you put in. That is relatively easy to test, and yet hardly any amateur ever does it. With stochastic software, by definition and design, the outputs cannot be predicted. Is it even possible to test that?
Well, yes it is, but it is far from easy, and ultimately the quality of the software is a matter of judgement and probability rather than proof. To get an idea of just how complicated it can be, read this article that describes one approach.
Professional testers struggle to test stochastic software adequately, amateurs almost always go by the ‘smell test’. If it smells right, it is right.
Unfortunately, it can smell right and still be quite wrong. Because of the repetitive nature of stochastic systems, small errors in endogenous variables can amplify exponentially with successive iterations. If a sufficient number of loops is not tested, these amplifications may well not be noticed, even by professionals.
I recall testing a system for ONS that projected changes in small populations. This was to be used for long term planning of education, medical, transport and utilities resources, amongst other things, over a period of 25 years. A very extensive testing programme was conducted and everything ‘looked right’. The testers were happy, the statisticians were happy, the project manager was happy.
However, shortly before the system was placed in production use, it was accidentally run to simulate 40 years instead of 25 and this produced a bizarre effect. It was discovered that the number of dead people in the area (used to calculate cemetery and crematoria capacities) was reducing. Corpses were actually being resurrected!
The fault, of course, was initially tiny, but the repeated calculations amplified the changes in the endogenous variables exponentially and eventually the effect became obvious. This was in software that had been specified by expert statisticians, designed and developed by professional creators, and tested by me. What chance would amateurs have?
There are ways to test stochastic processes in deterministic ways but these work on similes of the original code, not the code itself. These are also extremely long-winded and expensive to conduct. By definition, stochastic software can only be approved based on a level of confidence, not an empirical proof of fitness for purpose.
Stochastic processes should only be used by people who have a deep understanding of how a process works, and this understanding may only be gained by osmosis from actually running the process. Although the projection depends on randomicity, that randomicity must be constrained and programmed, thus rendering it non-random. The success or failure of the projection is down to the choice of the variables used in setting the amount of random effect allowed in the calculation – too much and the final output envelope is huge and encompasses practically every possible value, too little and the calculation may as well be deterministic.
Because of the difficulties in testing stochastic software, eventually it always turns out that placing it into production use is an act of faith. In the case in point, that faith has been badly misplaced.
Mony a Mickle Maks a Muckle
Testing stochastic software is devilishly difficult. The paradoxical thing about that is that the calculations involved in most stochastic systems tend to be relatively simple.
The difficulties arise with the inherent assumptions and the definitions of the variables implicated in the calculations. Because the processing very often involves exponential calculations (we’ve heard a lot about exponential growth over the past 24 months), any very slightly excessive exponent can quickly amplify any effect beyond the limits of credibility.
To explain how exponential growth works, here are .01, .02, .05 and 0.10 exponential growths over 25 cycles. So for .05 growth per cycle each number is increased to the power 1.05, i.e., x = x1.05. The actual ‘exponent’ is the little number in superscript.

You can see from this table what an enormous difference a very small change in exponent can make – changing from 0.01 to 0.10 growth leads to a multiplying factor of about 900 over 25 cycles.
Now imagine that these results are being used as exponents in other calculations within the same cycles and the scale of the problem quickly becomes apparent. The choice of exponent values is down to the researcher and accurately reflects their own biases in the understanding of the system behaviour. In the case of infections, an optimist may assume that not many people will be infected from a casual encounter whereas a pessimist could see an entire city infected from a single cough.
This illustrates what a huge difference a very small mistake of judgement can produce. If we had been considering the possibility of a Covid-infected person passing that infection on to another person within any week was about 10%, then by the end of six months he would have infected over 1,800 people Each of those 1,800 would also have infected 920 others, and those 920 would have infected 500, and so on and so on.
However, if the real infection rate was just 1%, then the number of people affected after six months would probably not be more than a large handful. (This is massively over-simplified and ignores things like effectiveness of treatments, seasonality, differing strains and many more factors. But then, apparently, so does Neil Ferguson’s software.)
Many of the factors implicated in such calculations simply cannot be known at the outset, and researchers may have a valid reason to err on the side of caution. But in normal circumstances a range of scenarios covering the most optimistic, most probable and most pessimistic states would be run, with confidence levels reported with each.
As time passes and real world data is gathered, the assumptions can be tuned against findings, and the model should become more accurate and better reflective of the real world. Unfortunately, there is precious little evidence that Neil Ferguson ever considers the real world as anything other than incidental to his activities.
Remember that what we are considering is a code monolith – a single huge collection of programming statements that has been built up over many years. Given that the codebase is built up of C++, Erlang and R routines, its development may well have begun at the tail end of last century. It is extremely likely that its oldest routines formed the code that was used to predict the expected outcome of the 2001 outbreak of foot and mouth disease in the U.K. and it has been steadily growing ever since.
To gauge just how good its predictive capabilities are, here are some notable mortality predictions produced using versions of this software compared to their real-world outcomes. (An order of magnitude is a factor of 10 i.e., 100 is one order of magnitude greater than 10.)
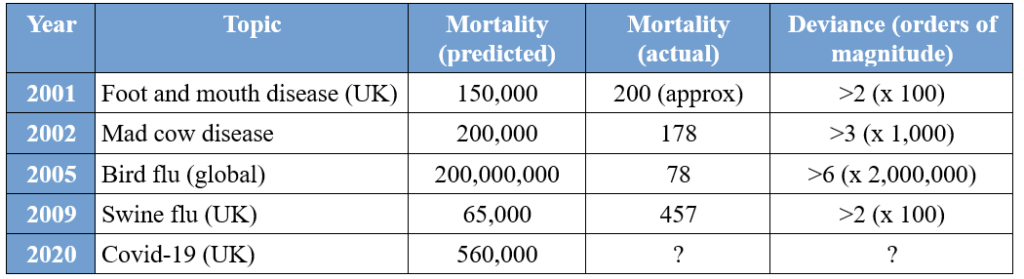
As we can see, the models have been hopelessly pessimistic for more than two decades. We can also see that, if any review of the model assumptions had ever been carried out in light of its poor predictive performance, any corrections made haven’t worked.
It appears that the greater the expected disaster, the less accurate is the prediction. For the 2005 bird flu outbreak (which saw a single infected wild bird in the U.K.) the prediction is wrong by a factor of over 2,000,000. It’s difficult to see how anyone could be more wrong than that.
I haven’t included a number for COVID-19 mortality there because it has become such a contentious issue that it is very difficult to report or estimate it with any confidence. A widely-reported number is 170,000, but this appears to be for all deaths of/with/from/vaguely related to COVID-19 since January 2020. In 2020 in England and Wales there were about 60,000 more deaths than in 2019, but there were only 18,157 notifications to PHE of COVID-19 cases, some, many or most of whom would have recovered.
As a data professional, it has been heartbreaking to watch the perversion, indeed the subversion, of data collection processes over the past two years. Definitions and methods were changed, standards were lowered and even financial inducements apparently offered for particular classifications of deaths.
Don’t Look Back in Anger – Don’t Look Back at All
I noted above that there seemed to have been precious little feedback from the real world back into the modelling process. This is obvious because over the period since the beginning of this panic there has been no attenuation of the severity of the warnings arising from the modelling – they have remained just as apocalyptic.
One of the aspects of the modelling that has been slightly ignored is that the models attempted to measure the course of the viral progress in the face of differing levels of mitigations, or ‘non-pharmaceutical interventions’ (NPIs). These are the wearing of face masks, the closure of places where people would mix, quarantines, working from home, etc. In total there were about two dozen different interventions that were considered, all modelled with a range of effectiveness.
The real world has stubbornly resisted collapsing in the ways that the models apparently thought it would, and this resilience is in the face of a population that has not behaved in the way that the modellers expected or the politicians commanded. Feeding accurate metrics of popular behaviour back into the Covid models would have shown that the effects expected by the models were badly exaggerated. Given that most people ignored some or all of the rules and yet we haven’t all died strongly suggests that the dangers of the virus embodied in the models are vastly over-emphasised, as are any effects of the NPIs.
On top of this we have the problem that the ways in which data was collected, collated and curated also changed markedly during the first quarter of 2020. These changes include loosening the requirements for certification of deaths, removing the need for autopsies or inquests in many cases, and the redefining of the word ‘case’ itself to mean a positive test result rather than an ill person.
At the start of the panic, the death of anyone who had ever been recorded as having had Covid was marked as a ‘Covid death’. This did indeed include the theoretical case of death under a bus long after successful recovery from the illness. Once this had been widely publicised, a time limit was imposed, but this was initially set at 60 days, long after patients had generally recovered. When even the 60-day limit was considered too long it was reduced to 28 days, more than double the time thought necessary to self-quarantine to protect the wider population.
There are other problems associated with the reporting of mortality data. We noted before that only 18,157 people had been notified as having a Covid diagnosis in England and Wales in 2020, yet the number of deaths reported by the government by the end of the year was about 130,000. It seems that this includes deaths where Covid was ‘mentioned’ on the death certificate, where Covid was never detected in life but found in a post mortem test, where the deceased was in a ward with Covid patients, or where someone thought that it ‘must have been’ due to Covid.
Given the amount and ferocity of the publicity surrounding this illness, it would be more than surprising if some medical staff were not simply pre-disposed to ascribe any death to this new plague just by subliminal suggestion. There will also be cases where laziness or ignorance will have led to this cause of death being recorded. If, as has been severally reported, financial inducements were sometimes offered for Covid diagnoses, it would be very surprising if this did not result in many more deaths being recorded as Covid than actually occurred.
Conclusions
Stochastic modelling is traditionally used to model a series of possible outcomes to inform professional judgement to choose an appropriate course of action. Projections produced using modelling are in no way any kind of ‘evidence’ – they are merely calculated conjecture to guide the already informed. Modelling is an investigative process and should never be done to explicitly support any specified course of action. What we have discovered, though, is that that is exactly how it has been used. Graham Medley, head of the SAGE modelling committee and yet another professor, confirmed that SAGE generally models “what we are asked to model”.
In other words, the scientists produce what the politicians ask for: they are not providing a range of scenarios along with estimates of which is most likely. Whilst the politicians were reassuring us that they had been ‘following the science’, they never admitted that they were actually directing the science they were following.
To demonstrate how different from reality the modelling may have been, we can simply examine some of the exogenous variables that are hard set in the code. In one place we find an R0 (reproduction) value of 2.2 (increasing quickly) being used in May 2020 when the real R0 was 0.7 to 0.9 (decreasing) and in March 2021 a value of 2 (increasing quickly) was being modelled when the real-world value was 0.8 to 1.1 (decreasing quickly to increasing slowly). Using these values would give much worse projections than the real world could experience. (As an aside, defining the same variable in more than one place is bad programming practice. Hard-coding is not good either.)
This admission has damaged the already poor reputation of modellers more than almost anything else over the past two years. We always knew that they weren’t very good, now it seems they were actively complicit in presenting a particular view of the disease and supporting a pre-determined political programme. Why they have prostituted their expertise in this manner is anyone’s guess but sycophancy, greed, lust for fame or just simple hubris are all plausible explanations.
One of the most serious criticisms of the Covid modelling is that it has only ever modelled one side of the equation, that of the direct effects of the virus. The consequential health and financial costs of the NPIs were never considered in any detail but in practice seem likely to hugely overshadow the direct losses from the disease. No private organisation would ever consider taking a course of action based on a partial and one-sided analysis of potential outcomes.
Wouldn’t it have been good if the software used to justify the devastation of our society had been subject to at least a modicum of disinterested oversight and quality assurance? Perhaps we need a clearing house to intervene between the modellers and the politicians and safeguard the interests of the people. It would surely be useful to have some independent numerate oversight of the advice that our legal or classically-trained politicians won’t understand anyway.
The best thing that can be said about the modelling that has been used to inform and support our Government’s response to the Covid virus is that is probably much better quality and of higher integrity than the nonsensical and sometimes blatantly fraudulent modelling that is ‘informing’ our climate change policy.













To join in with the discussion please make a donation to The Daily Sceptic.
Profanity and abuse will be removed and may lead to a permanent ban.
Anything that helps to discredit Ferguson is welcome, but the problem is not really the code, it was and is the assumptions the modelling was based on, that were flawed at the time and not revised at any stage in the light of real world experience, and the unwillingness of anyone involved (Ferguson and his colleagues, SAGE, the government) to re-examine their conclusions and actions – they simply doubled down and lied, and then started manufacturing evidence to justify their policies, not the other way round.
It’s not a failure of science as such but of honesty, character, incentives.
I mentioned some of the assumptions towards the end of the article and pointed out that the assumptions of infectivity (R) were much higher than in real life.
Finding other variable would have meant wading though the code to discover them and life is too short.
Great summary.
The whole affair an indictment of a superficial style of government, permanent electioneering over competence in office, minted by Clinton, imported by Blair and carried on by all subsequent governments.
On the upside, a massive opportunity awaits for a sincere, competent and attractive leader, particularly since Beer Starmer is not of that ilk.
Brilliant and would be hilarious, hysterically funny, if made into a spoof movie (Spinal Tap style) about modellers and Prof Pantsdown but who would dare?
And, of course, this is the real reason that Bunter had to go, revealed as a complete no hoper for appointing Hancock, listening to Pantsdown, Whitty etc., and not commissioning, publishing, a detailed cost benefit analysis.
Bunter: a rank incompetent; total buffoon.
In this film the scare setting would be at least 11.
David,
A huge thank you for writing this article. A really interesting review from a knowledgeable professional.
Truly humbling for people not in the field.
Thank you again.
Julian
Thanks Julian, I’m glad you enjoyed it.
I quite enjoyed researching and writing it. I have seen a lot of bad code but even I was unprepared for just how bad this is.
Excellent stuff, thank you. Read every word, and I’ve worked in the specific field of Data Science for the last ten years. This is another DS article I have printed out, so I can read it again with notes.
I was telling people (including my IT colleagues) in 2020 about the fact that Neil’s team’s work had been producing predictions for the last twenty years that were AT LEAST one order of magnitude out. And then wondering very publicly (I repeatedly emailed the top brass of my 70,000 strong global company) about why so many governments were suddenly believing Neil Ferguson’s BS. I can only conclude that a certain Bill Gates “did the rounds” and pressed the flesh.
I even browsed the GitHub after “Sue Denim” (the ex Google engineer) pointed me to it. I was immediately shocked, but was simply too busy at the time with my day job to give it any deeper investigation. And to think the actual code is still secret… probably because it’s an even bigger “shit tip”.
Thanks again. If I hadn’t all but decided to leave the world of IT (for many of the reasons held in this article), I would make your level of expertise my aim in life. As it is, we have started to live a much simpler life in the sticks.
Cheers! The geek shall inherit the earth.
Hello World.
Thanks Marcus. Up the geeks!!
I’d also be interested to know what your notes were.
If only Boris had had the cojones to say; “I’m terribly sorry but when I returned from my stay in hospital with covid I was easy prey to Whitty, Vallance et al & got sucked in to their doom loop, a classic case of Stockholm syndrome. I now see it was all balls, none of it made a blind bit of difference, I’ve sacked them all, forbidden mention of the word covid and we’re going back to normal.”
The sooner he’d done it the less bad off him & the rest of would have been.
But for the fact that Boris is – in the words of Jonathan Sumption QC – intellectually idle.
That was all his wife’s doing, courtesy of Zak Goldsmith
A fine article – thank you.
To quote Feynman – “Science is the belief in the ignorance of the experts”. And Feynman again (from memory) – “It doesn’t matter how beautiful your theory is – if it doesn’t agree with the measurements – it’s wrong”.
The penultimate paragraph seems key to me in summarising our dilemma as a society – who is there to referee the models/research in a properly independent manner? Or, put another way, who is courageous enough to speak out when your career is on the line for not going along with the prevailing consensus?
The most egregious example for me is the role of models in climate “science”. These have a fiendish number of input variables, are at least partly recursive and almost always run far too hot when measured against the empirical evidence. I find it significant that many, probably most, of the few professional scientists and statisticians actively critiquing here are retired or independent of government funding.
We desparately need a “red team” vs “blue team” approach when considering such important matters.
About 40 years ago the Department of Defense ran a competition to produce a new computer language, this had Red, Blue, Yellow and Green teams from different companies. The DoD decided which option met their specification the best, which I think was the Green team, and Ada was born.
If political decisions are being made on the basis of computer models then they need to be of the highest quality possible. No one would accept a physical construction that flapped in the slightest breeze, no one would fly in an aircraft that hadn’t been tested to the limits of its envelope. We’ve all seen the problems when corners have been cut in the space programme for example.
One my colleagues tried, in the aftermath of Ferguson’s modelling, to gather a group of real experts together for just that purpose. I would have been one of them.
The effort failed, I think mainly because nobody believed that politicians were capable of believing what they didn’t want to hear.
Thank you for your kind words and yes, I absolutely agree that we cannot ever again smash our society using the uncorroborated opinion of a proven failure as justification.
I spent 15 years at Imperial doing engineering research. I wrote plenty of code to process data and make predictions concerning sound wave propagation. The mathematics and code involved produced extremely reliable predictions and repeatable results for any user.
I am pleased with the quality of the work I did during that time.
What a plonker Ferguson is and his team. I suggest their code is binned. Not fit for purpose
How lazy and dumbed down the access media are. No models of anything from global warming to pandemics are critiqued, but presented as science and truth.
Speaking as someone who has done lots of electircal simulation.
I bet you’re glad your’re away from there now. Ferguson has done a severe disservice to the cause of mathematical modelling.
A so-called race condition is said to exist in a program when the outcome of a particular operation depends on an ordering of independent events, but no specific ordering is enforced by the code. This mirrors a real race where some number of participiants run the same distance on parallell lanes and it’s a priori unknown in which order they’ll arrive at the finishing line. A contrived scenario illustrating why this can cause problems could be two people tasked with filling a watering can. One takes the can and races to place it below the tap, the other races to the tap to open it. Depending on who arrives first, water will or won’t end up being spilled on the floor. Obviously, humans won’t make such a mistake. But computers will happily do.
Never trust an expert incapable of explaining what he’s talking about in plain language. This almost certainly means he doesn’t understand it himself.,
Exactly – the question that starts “But in plain terms” is a very powerful one.
One of the worst questions a top exec once asked me was, “Yesyesyes, but before we go live with this we need to know that you are happy your code does what it is supposed to do – are you?”
When I responded that it simply should not be my duty to say such a thing, I got an over-the-top-of-the-glasses glare.
When I went on to say that I had not even received a proper specification or Definition of Done (DoD) from anyone in the business, she closed her notebook and left.
When she came back to me a couple weeks later, telling me “your numbers are wrong”, I closed my notebook and left.
I feel your pain.
A brilliant analysis of the shortcomings of pantsdowns useless modelling history.
I read this as a total novice of the area and sort of understand where the author has issues.
As somebody who does not really understand programming beyond the very basics it strikes me that the old adage of “crap in crap out “applies here in spades.
My real concern though is that apparently nobody in “power” had the nous to look at this modelling and say ” hang on guys this does”nt look right”
We have all been conned royally .
Thank you.
I’m not sure that anyone in power actually wanted to question something from a previously-respected institution that was supporting their own aims. Not that many of them would have understood if told…
I don’t think anyone will be gobsmacked to read that Ferguson is not just an incompetent modeller but also an amateurish coder. The detail is pretty interesting I suppose.
What is intriguing to me is that the UK apparently needed Ferguson’s absurd models to decide to lockdown when most of western Europe had already done so without the need for models.
Italy, Spain, France etc just went into panic mode and locked everyone up. The UK went into panic mode, but needed to pretend it wasn’t panicking by presenting a veneer of rationality. Like they’d done some sums and yes indeed millions were going to die. So we weren’t panicking like those excitable Italians, we were bothering to work it out first before diving in.
This is how so much public policy in the UK is conducted (and elsewhere too, I suppose). Political decisions are so often presented under the guise of expert deliberations and advice.
Evidence-based decision making is so passé.
Decision-based evidence making is sooo much easier.
I think that’s a pretty good summary of the situation in March 2020.
Would have been nice to have seen this analysed within about 12 hours of it first appearing, by someone with the clout to shake Ferguson until his teeth rattled. Instead…?
It was analysed, in April-May-June 2020, and found seriously wanting. Indeed, the job of taking the original codebase from Imperial, and sorting it out enough to put it on GitHub (not very well) was enough to be able to say it was rubbish. The engineers involved saw it was rubbish; Issue #161 as a case in point. But the MSM was under orders to ignore anyone who undertook this sort of thing and wanted to draw their attention to the huge problems.
I don’t think that such a person exists, Ferguson appears to be flame-proof.
Remember, too, that even the sanitised code wasn’t made public until some weeks after the event.
Far too technical for me personally but I persevered with it, as this is another important component of the multi faceted enterprise fraud carries out against humanity starting 2020; The fact it was not updated after mid 2021 is telling; if there was a genuine desire to track and predict the course of a real outbreak, then of course it would have been refined, improved and redeployed. There was no pandemic though; there was only a crime against humanity. Computer modelling was only needed to provide a fig leaf for pre-planned offensive actions in early 2020; part of a campaign to terrorise and subdue the population, forever alter the social contract and remake the economic system. I recommend that everyone rewatch Boris Johnson’s announcement of the first lockdown as I did yesterday. With the benefit of hindsight, his lies, manipulations and culpability are clearly on display. The queen’s speech is also worth a rewatch. By my estimation thousands of individuals were involved, and we will continue to be menaced and assaulted by these people until they are behind bars.
I think there was a pandemic, just not a very dangerous one, hence the 19th March 2020 decision to downgrade COVID-19 from a HCID.
And yes, I agree it was a fig leaf.
Sars-Cov-2 was pandemic in the sense that oxygen (the breathable type, two atoms) is pandemic.
Interestingly, oxygen is poisonous, and starts killing us slowly the instant we take our first breath.
An executive summary would have been nice for those of us not inclined to plough through the minutæ.
The executive summary is “Prof Neil Ferguson writes code that cannot do what it says it does, and has done foe many years.
HTH
Software engineer with apparently very limited experience[*] who firmly believes in beancounting as solution to any problem finds Imperial project management wanting in procedures he considers essential.
[*] Must obviously have missed out on the entire open source development since the late 1980s and can only be very passingly aware of the history of UNIX, both highly productive and successful examples of not following most of these essential procedures.
Former UNIX admin who requires software to do what it is meant to do.
There are no functional tests, and no high-level test plans nor any test strategy. There is no way for a disinterested tester to make any adequate assessment of the quality of this software. This is extremely poor practice.
In this case, you should certainly be aware that this is extremely common practice, as there are lots of large software projects (Linux would obviously come to mind here) with no formal QA whatsoever.
Indeed, but most of those projects are not used to justify smashing up our entire culture, economy, freedoms, future…
They just fail and isolated invested parties lose money (sometimes someone is injured or dies, sure).
As reply to the text I wrote, this statement makes absolutely no sense and you must be aware of the fact that you’re asserting an outright falsehood.
You’re going to have a hard job persuading me otherwise.
The only alternative that I can see is colossal incompetence. Which is worse?
We may have crossed wires here, RW. I agree that much software is released without anything other than Unit Tests (i.e. tested only by the developers themselves, which obviously is unsatisfactory and leads to many problems). Software/models built amateurishly to justify locking us all down (or not, hopefully) should really be held to a much higher standard – if at all. Are we straight? 👍
Yes, there are, many of them in public-sector operations, although by no means all.
If there are no specifications how do you know what the system is meant to do? How will you know if it does it?
‘… they are merely calculated conjecture to guide the already informed.’
Not these days, they are used to fill the empty minds of dumb politicians by people who have agenda to pursue.
Another thought but blindingly obvious is the ” modelling” carry over into the whole climate change/nett zero malarky .
Again historical real data is ignored or adjusted out to make the calamity scenario the only one that is promoted.
Its only a model …not reality .Idiots all.
Would have been interesting to compare to a model some properly qualified epidemiologists (such as The Great Barrington group) would have created using qualified and experienced software developers. Oh! But that wasn’t the purpose of the exercise, was it.
Professor Bankruptcy wasn’t the problem. It was the cretins in power who listened to him. 3 years of our lives we’ll never get back.
Quite an effort. Thank you, I think we get the picture. Now how about sending to every MP, every cabinet member, when there is one and every msm outlet to be broadcast to the sheeple. Publish this info in journals dealing with the subject of modelling, science, infectious diseases. In addition a demand, not a suggestion, Neil Ferguson be removed from his job with immediate effect. Of course that should have been done two years ago, but with such an impotent group in government and in sage, that was not possible.
I don’t think it would do any good, it’s very difficult to get any of them to actually read anything.
I once contributed to a House of Lords inquiry and emailed a Baroness directly to tell her that a government agency had lied to her in the House but didn’t even get an acknowledgement.
A superb article and some excellent, perceptive comments.
Here, I just want to emphasise a point.
Firstly, it was well known, even before Shi Zhengli developed the virus and Xi Jinping sent it arount his Belt & Road connections, that Neil Ferguson was an arrogant, shroud waving incompetent. Of course he can and should be blamed and punished. Just like Admiral Byng, “‘pour encourager les autres”.
But what I want to know is as follows: – It is inconceivable that someone just looked in an old copy of The Yellow Pages and picked out with a pin Ferguson and the Imperial team to head up the “Projection” part of the response to Covid. Some Civil “Servant”, or “Advisor” MUST have picked them, knowing their background, deliberately. So who was it? Dominic Mckenzie Cummings? Was it to ensure that Boris would not be blindsided if (say) Kneel Starmer had used Ferguson whilst Boris was using someone slightly sensible?
Whatever. But I suggest that anyone who WAS involved in the selection of this pantsdown nitwit, should be forced to defend themselves on a legal charge of Gross Misconduct in Public Office.
But there also needs to be a strong mechanism to guard against the ever popular Policy Based Evidence Making, as practiced for all this Millenium (and before) by the inept arts-grad politicians and their annointing of ridiculae as “Settled Science” that no one can be permitted to question.
Thank you.
Neil Ferguson has been the “go-to guy” ever since the most recent foot and mouth outbreak. I think that initially he just bamboozled the politicians with numbers but managed to become part of the furniture.
Sponsorship by the Bill and Melinda Gates Foundation will not have been harmful at all.
Totally agree re the arts-grad type of politician – that’s why none of them would qualify to be Reform UK candidates.
Excellent stuff even though, like I imagine most DS readers, I haven’t actually read it and in a way don’t need to. The fact that these so called experts are oblivious to obviously coherent criticism and can’t even be bothered to respond, and that hardly any politicians even care, says it all. I think we are in a civilizational crisis when this kind of incompetence is routine and the vast majority of our MPs are a bunch of useless and incompetent morons!
Re MPs I should of course have added unprincipled!
Re hardline prolockdowner Ferguson and his modelling in Imperial College Report 9.
The lead paragraph of Report 9 says: “The global impact of COVID-19 has been profound, and the public health threat it represents is the most serious seen in a respiratory virus since the 1918 H1N1 influenza pandemic.”
On what basis did Ferguson compare COVID-19 to the 1918 pandemic?
His report is dated 16 March 2020.
Let’s say he considered data from a week earlier when writing the report, say 9 March 2020. According to Worldometers, 4,037 deaths had been attributed to Covid-19 on 9 March 2020. If we take that number as reliable…and it’s a BIG IF about any of this stuff…4,037 deaths globally is a very small figure. So where does Ferguson get off comparing it to 1918…which reportedly resulted in 50 million deaths…?
If he’s comparing to other pandemics, why not 1957/1958 or 1968 or 1976 or 2009?
No…he goes for 1918, 50 million deaths. He should have been called out right then, but he wasn’t.
A few days later, Public Health England reported: “As of 19 March 2020, COVID-19 is no longer considered to be a high consequence infectious disease (HCID) in the UK”.
According to Public Health England (PHE):
(My emphasis.)
It was also noted that “The Advisory Committee on Dangerous Pathogens (ACDP) is also of the opinion that COVID-19 should no longer be classified as an HCID”.
How did Ferguson get away with beating up the fear about Covid, when PHE came out less than a week later acknowledging mortality rates were low overall? I challenged Ferguson about this at the time, see my email: Neil Ferguson and Andrew Pollard sharing a taxi…?, 5 August, 2021.
“…now it seems they were actively complicit in presenting a particular view of the disease and supporting a pre-determined political programme”
Just like the Climate Models!
Thank you so much for your analysis.
You write “Why they have prostituted their expertise in this manner is anyone’s guess …..”
Well one of the explanations is that many of the Ferguson type are staunchly anti-capitalist. Universities have always been hotbeds of Trotskyists. Most will be members of the climate-change cult so they saw this as a unique opportunity to sabotage society, and of course the gormless government fell for it.
Yes, I rather suspect your are correct.
A superb analysis. What a scandalous state of affairs.
Thank you. I have to agree that it is indeed scandalous.
A superb analysis -thank you. But what a pity that your critique, along with so much valuable material collected on here by Toby Young, will never enter the consciousness of the majority of our fellow citizens. They have, of course, been brainwashed by the government’s lavishly-funded propaganda.
Who did the first table under Mony a Mickle Maks a Muckle? I have to query it. For example, an initial value of 2 and an exponent of 1.1 gives 1,836 after 25 cycles. Does it? Raising 1.1 to the power 25 and making the result the exponent of 2 yields 1,836. But that’s not how exponential growth is worked out.
You’re right. I did the table quickly as I was writing the article and stuck in that progression quickly just for completeness. The problem was I forgot to revisit it and do it correctly. I’ll do that and come back here with the correct end values for exponential growth.
However, it may not be as wrong as first appears. I used the phrase “exponential growth” because it was heard a lot in popular coverage. I really have no idea what types of progression actually appear in this code – it could be exponential, geometric or arithmetic or combinations of all three, I just haven’t looked in detail.
Most probably, though, I think it will be exponential.
OK, I ran the numbers again, using the correct exponential growth formula V = S x (1 + X)t
This gives us the following for S = 2:
% growth (X) / cycle (t) 10 25 50 75 100
1% 2.2 2.6 3.3 4.2 5.4
2% 2.4 3.3 5.4 8.8 14.5
5% 3.3 6.8 22.9 77.7 263
10% 5.1 21.7 234.8 2,543 27,561
So the difference at 25 cycles isn’t as much as in the original table, a bit less than one order of magnitude here. But this chart shows the power of an exponential progression as, by the time the 100th cycle is reached, the difference is more than 500 orders of magnitude (5,000 times).
100 cycles may seem excessive but each of these may be only a single day and 100 cycles is about three months.
Even today, in July 2022, R0 is being estimated as being 1.1 to 1.3, about 2% – 5% (it’s a lagging indicator, estimated by judgement and consensus) so that would be in the middle of the table. Remember, though, that we have seen values for R0 of around 2 which equates to about 100% so after 25 cycles this would encompass more than the entire population of England.
So, sorry for the slight confusion (mea culpa), but I hope this explanation makes things clearer.
This is the most scientific dissection – or perhaps more accurately dismemberment – of the Covid modelling that I have seen. I had always assumed that the various assumptions were wrong, but it is a killer blow to find the coding was also faulty. Mind you this is not unknown in the NHS. Some of the major patient administration systems looked, in their early iterations, like Windows type programs but on analysis they turned out to be running over a background of MS-DOS or even earlier programming languages.
Amateur programming should be for the birds. When will they ever learn?