
The ‘Twitter Files’ have exposed numerous contacts between US government officials and Twitter and requests for suppression of accounts or content: notably, in the context of alleged COVID-19 ‘disinformation’. But what they have not revealed is that there was in fact a formal government programme explicitly dedicated to “Fighting COVID-19 Disinformation” in which Twitter, as well as all other major social media platforms, were enrolled.
As part of this program, the platforms were submitting monthly (later bi-monthly) reports to the government on their censorship efforts. Below is a picture of an archive of the “Fighting COVID-19 Disinformation” reports.
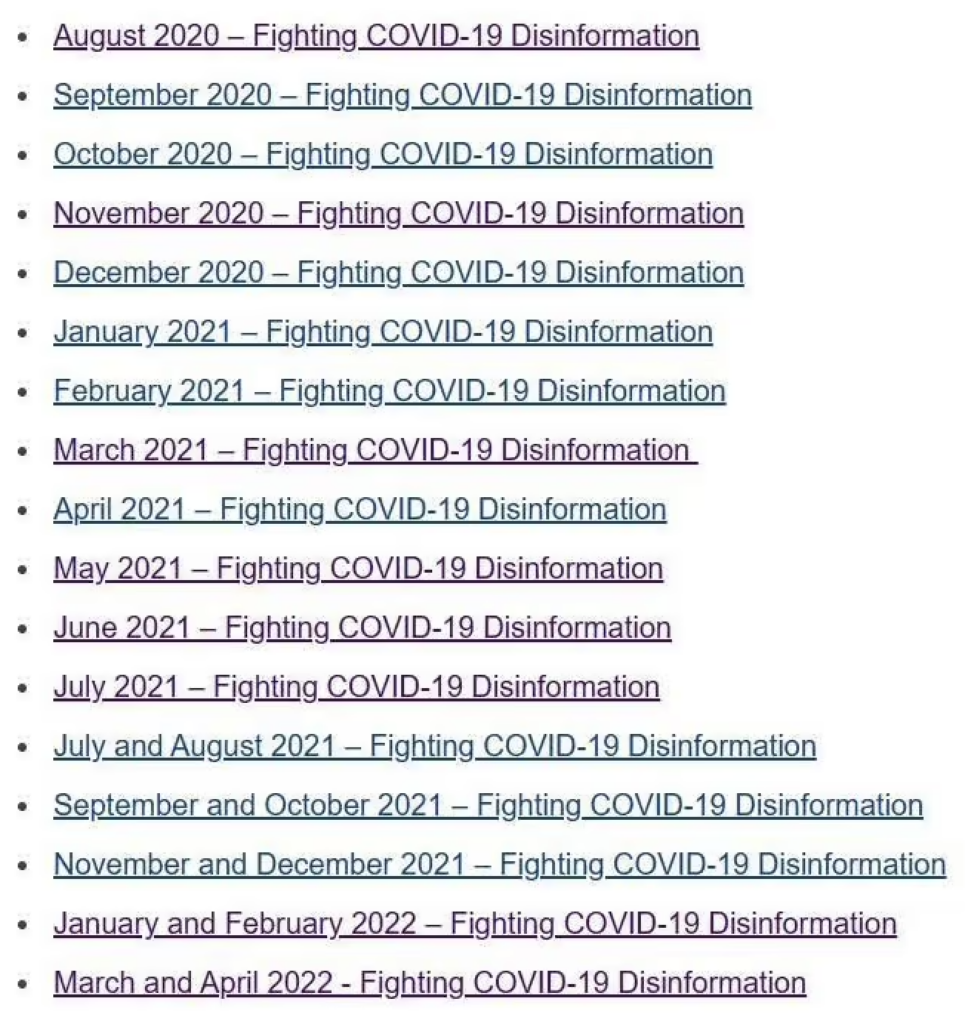
I did not have to hack into the intranet of the U.S. government to find them. All I had to do was look on the public website of the European Commission. For the government in question is not, after all, the U.S. government, but the European Commission.
The reports are available here. Lest there be any doubt that what is at issue in “Fighting COVID-19 Disinformation” is censorship – but how could there be any doubt? – the Commission website specifies that the reports include information on “demoted and removed content containing false and/or misleading information likely to cause physical harm or impair public health policies” (author’s emphasis).
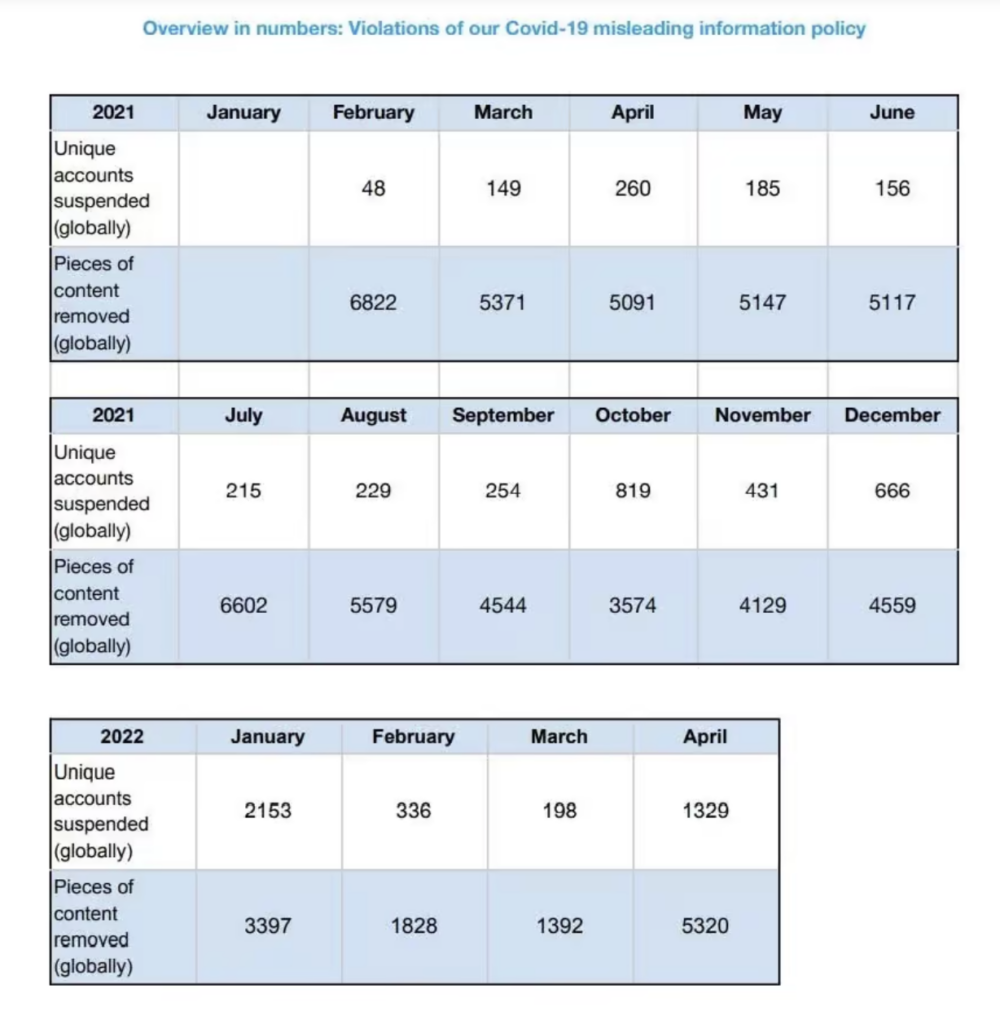
Indeed, the Twitter reports, in particular, include data not only on removed content, but also on outright account suspensions. It is thanks precisely to the data that Twitter was gathering to satisfy the EU’s expectations that we know that 11,230 accounts were suspended under Twitter’s recently discontinued COVID-19 Misleading Information Policy. The below chart, for instance, is taken from Twitter’s last (March-April 2022) report to the EU. Note that the data is ‘global’, i.e., Twitter was reporting back to the European Commission on its censorship of content and accounts all over the world, not just in the EU.
To be clear then: It is strictly impossible that Twitter has not had contact with EU officials about censoring COVID-19 dissent, because the EU had a program specifically dedicated to the latter and Twitter was part of it. Furthermore, it is strictly impossible that Twitter is not continuing to have contact with EU officials about censoring online content and speech more generally.
This is because the EU’s “Fighting COVID19 Disinformation” program was launched within the framework of its more general so-called Code of Practice on Disinformation. Under the Code, Twitter and other online platforms and search engines have assumed commitments to combat – i.e., suppress – what the European Commission deems to be ‘misinformation’ or ‘disinformation’.
In June of last year, a ‘strengthened’ Code of Practice on Disinformation was adopted, which created formalised reporting requirements for Code signatories like Twitter. Other major signatories of the Code include Google/YouTube, Meta/Facebook, Microsoft – which is notably the owner of LinkedIn – and TikTok.
Furthermore, the strengthened Code also created a “permanent task force” on disinformation, in which all code signatories are required to participate and which is chaired by none other than the European Commission itself. The ‘task force’ also includes representatives of the EU’s foreign service. (For more details, see Section IX of the Code, titled “Permanent Task-Force.”)
And if this were not enough, in September of last year, the EU opened a ‘digital embassy’ in San Francisco, in order precisely to be close to Twitter and other leading American tech companies. For the moment, the embassy reportedly shares office space with the Irish consulate: meaning, per Google maps, that it is around a 10-minute drive from Twitter headquarters.
So, it is strictly impossible that Twitter has not had and is not continuing to have contact – indeed extensive and regular contact – with EU officials about censoring content and accounts that the European Commission deems ‘mis-’ or ‘disinformation’. But we have heard absolutely nothing about this in the ‘Twitter Files’.
Why? The answer is: because EU censorship really is government censorship, i.e., censorship that Twitter is required to carry out on pain of sanction. This is the difference between the EU censorship and what Elon Musk himself has denounced as “U.S. government censorship”. The latter has amounted to nudges and requests, but was never obligatory and could never be obligatory, thanks to the First Amendment and the fact that there has never been any enforcement mechanism. Any law creating such an enforcement mechanism would be obviously unconstitutional. Hence, Twitter could always simply say no.
But so long as it wants to remain on the EU market, Twitter cannot say no to the demands of the European Commission. As discussed in my previous article here, the enforcement mechanism that renders the Code of Practice obligatory is the EU’s Digital Services Act (DSA). The DSA gives the European Commission power to impose fines of up to 6% of global turnover on platforms that it finds to be in violation of the Code: n.b. global turnover, not just turnover on the EU market!
The Commission has not been shy about reminding Twitter and the other tech companies of this threat, thus posting the below tweet last June on the very day that the ‘strengthened’ Code of Practice was announced.

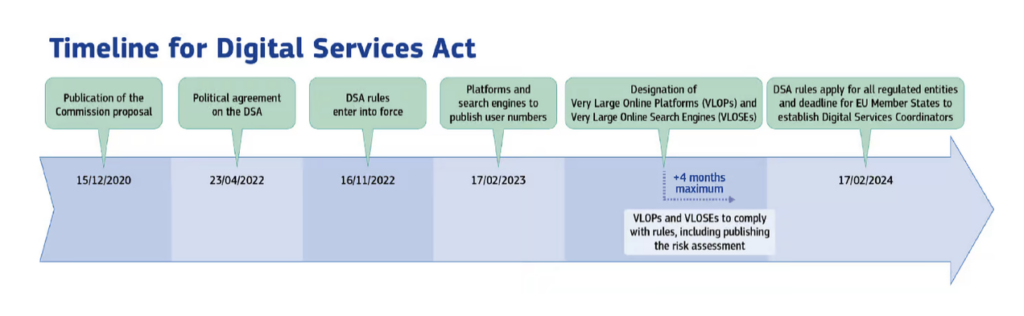
This was before the DSA had even been adopted by the European Parliament! But the DSA has been the sword of Damocles hanging over the heads of Twitter and the other online platforms for the last two years, and it is now law. Once designated a “very large online platform” by the Commission – which is inevitable in its case – Twitter will have four months to demonstrate compliance, as the below “DSA Timeline” makes clear.
Moreover, the power to apply financial sanction is not the only extraordinary enforcement power that the DSA gives the Commission. The Commission is also given the power to conduct warrantless inspections of company premises, sealing the premises for the duration of the inspection, and gaining access to whatever ‘books or records’ it pleases. (See Article 69 of the DSA here.) Such inspections, which have been previously used in the context of EU competition law, are quaintly known in the literature as ‘dawn raids’. (See here, for example.)
This is why Elon Musk and the “Twitter Files” are so verbose about alleged “US government censorship” and so willing to “out” the private communications of US government officials, but have remained suitably mum about EU censorship demands and have not outed the private communications of any EU officials or representatives. Elon Musk is being held hostage by the European Union, and no hostage in his or her right mind is going to do anything to irritate the hostage-takers.
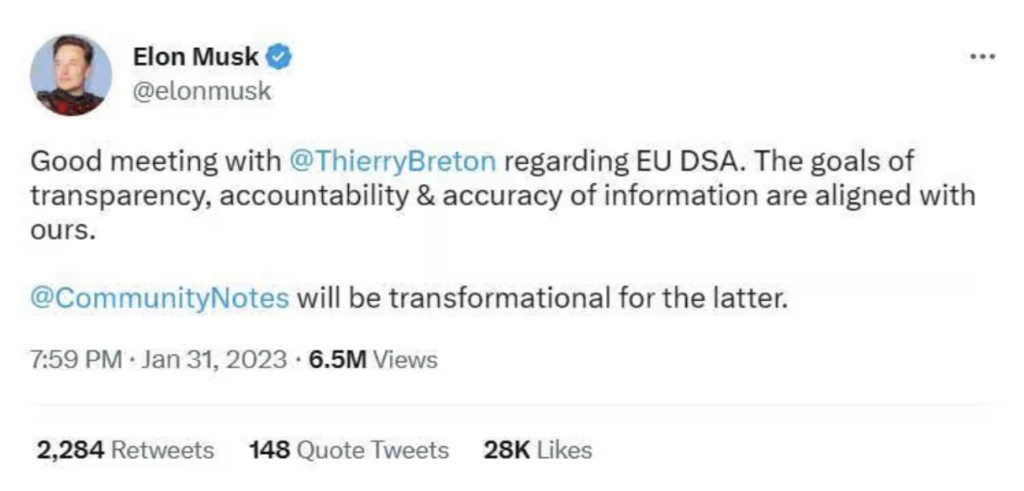
Far from any sign of defiance of the Code and the DSA, what we get from Elon Musk is repeated pledges of fealty: like the below tweet that he posted after meeting with EU Internal Market Commissioner Thierry Breton in January. (For an earlier such pledge in the form of a joint video message with Breton, see here.)
And if Musk should ever have any doubts about what he needs to do to satisfy the EU’s requirements, help is always close at hand – indeed a mere 10 minutes away. For the EU’s ‘digital ambassador’ to Silicon Valley, Gerard de Graaf, is one of the authors of the DSA.
But if Elon Musk is so fearful about crossing the EU, then why has he restored so many COVID-19 dissident accounts? Wasn’t that an act of defiance of the EU and notably of its “Fighting Covid-19 Disinformation” program?
Well, no, it was not.
Firstly, it should be recalled that Musk had originally promised a “general amnesty” of all suspended accounts. As discussed in my earlier article here, this quickly drew a stern and public rebuke from none other than Thierry Breton, and Musk failed to follow through. Instead, in accordance with Breton’s demands, there has been a case-by-case restoration of selected accounts, which has recently slowed down to a trickle.
@OpenVaet, whose own Twitter account remains suspended, has been maintaining a partial inventory of suspended Twitter accounts. As of this writing, only 99 of the 215 accounts in the sample, or roughly 46%, have been restored. (See @OpenVaet’s spreadsheet of still banned and restored accounts here.) Assuming the sample is representative, this would mean that over 6,000 accounts in all are still suspended.
And this is to say nothing of the more insidious form of censorship that is ‘visibility filtering’ or ‘shadow-banning’. Per the motto “Freedom of speech is not freedom of reach”, Elon Musk has never denied that Twitter would continue to engage in the latter. Many of the returning COVID-19 dissidents have noticed a curious lack of engagement, leading them to wonder if their accounts are not in fact still subjected to unannounced special measures.
But, secondly, and more to the point, have another look at the archive of the “Fighting Covid-19 Disinformation” reports shown above. That is the complete archive. The March-April 2022 reports are the final set of reports. Last June, as noted here, the European Commission discontinued the program, folding the reporting on COVID-19 ‘disinformation’ into the more general reporting requirements established under the ‘strengthened’ Code of Practice on Disinformation.
By this time, most of the most onerous COVID-19 measures in the EU, including ‘vaccine passports’, had already been ended, and most of the remainder have been gradually rolled back since. Elon Musk thus allowed (some) COVID-19 dissent back onto Twitter when, at least in the EU, there was hardly any public policy to dissent from anymore.
But the EU’s censorship regime as such is still very much in place, and censorship has by no means come to an end on Twitter. Thus, on the very night of the Brazilian elections on October 30th, Twitter was already censoring local reports of electoral fraud. The famous ‘misleading’ warning labels that had once been used to quarantine reports of COVID-19 vaccine harm now made a reappearance, insisting that according to unnamed ‘experts’, Brazil’s elections were ‘safe and secure’. (For examples, see my thread here.)
Whether electoral integrity/fraud in countries of interest, the war in Ukraine or the ‘next pandemic’ for which the EU is already reserving mRNA ‘vaccine’ capacity, you may rest assured that the EU will not lack new subjects of ‘disinformation’ requiring censorship and that Elon Musk and Twitter will oblige.
Whether this censorship takes the form of outright suspensions and content removals or content ‘demotion’ and account ‘visibility filtering’ is a secondary matter. The European Commission will be able to work out such details with Twitter and the other platforms.
Indeed, the DSA further requires the platforms to grant the Commission access to their back offices, including, as Thierry Breton triumphantly notes in a blog post here, “the ‘black box’ of algorithms that are at the heart of platforms’ systems”. As noted on the Commission website, the Commission is even setting up a European Centre for Algorithmic Transparency, in order to be able to better fulfill its ‘supervisory’ role in this regard.
Needless to say, such ‘transparency’ does not extend to mere users such as you or me. For us, the algorithmic functioning of the platforms will remain a ‘black box’. But the Commission will be able to know everything about it and to demand modifications to ensure compliance with the EU’s requirements.
Robert Kogon is a pen name for a widely-published financial journalist, a translator, and researcher working in Europe. Follow him at Twitter here. He writes at edv1694.substack.com. This article first appeared on the website of the Brownstone Institute.












To join in with the discussion please make a donation to The Daily Sceptic.
Profanity and abuse will be removed and may lead to a permanent ban.
Too bad the article was written under a pen name – a form of self
censorship.
Mind you, writing under my own name got me banned by The Times so I do wriggle on the hook of this issue.
The way things are progressing wrongspeak and wrongthought simply won’t be possible soon.
I fail to see why adopting the language of our oppressors, as in “wrongspeak and wronghtought” aid our cause. Helping to form a 1984 society via their isms is hardly pushing back. Hasn’t the woke vocabulary done enough damage?
Medical Misinformation: telling the truth about pharmaceutical products.
Stand in the Park Make friends & keep sane
Sundays 10.30am to 11.30am
Elms Field
near Everyman Cinema & play area
Wokingham RG40 2FE
It remains remarkable that, despite the plethora of readily available information on the fascism (as in the original meaning) between government, social media, MSM, big business and the technocracy, the majority of the populace remains quite content to believe and do what they are told.
In the end, it remains a case of caveat emptor, or ” we get the politicians we deserve”.
We don’t, individually we can only choose one. The one I voted for fights the tide, but is a lone voice.
Few and far between.
Congratulations on having a decent representative.
The idea that we can choose our political representatives is basically a fantasy.
And the idea that our political representatives have any real policy making power another even bigger fantasy.
Our democracy is like an elaborate card trick. You choose the card they want you to pick, and the card ends up where the trickster wants it to.
How would EU members communicate and transact without social media companies like Twitter? Would the EU find themselves in a communication blackspot if Musk pulled out of their jurisdiction?
I realise this is probably a stupid question but would it be inevitable that the likes of Gab and Gettr would simply move in, comply and clean up? I thought G and G prided themselves on their free speech ideals – but I suppose money talks.
I’m really getting to hate the EU more than is reasonable.
Nothing would please the EU and other establishments more than the disappearance of Twitter, and pretty much all social media.
It would mean they could go back to the good old days when all the information was easy to control – radio, TV, papers.
Social media has exposed the ruling establishment and they are desperate to put the genie back in the bottle with all their digital laws and controls.
The “disinformation” and “misinformation” has rolled the curtain back to reveal the fraud that is our free democratic system and the establishment is cross, very cross.
Is Twitter UK subject to EU social media censorship rules?
So what did we expect from the unelected and venal bureaucrats in the EC, honesty and openness? The book ‘Adults in the Room’ by Yanis Varoufakis tells us all we need to know about corruption and the abuse of power in the organisation.
The EU consists almost entirely of former Fascist or Communist nations. And its run by people who have very close links with the previous generations of Fascists and Communists who ran their countries.
It’s hardly surprising that the EU they’ve built has all the surveillance, authoritarian and dictatorial features of a Fascist/Communist State. It’s all they know.
Thank the Lord we’re out of it.
When bureaucracies and politicians get asked or even told to do something they don’t want to do, their best method of counter-action is agree to it, then do nothing. This works at every level government. I hope Twitter is adopting a similar policy – agreeing in public but doing little or nothing in private. Of course, when they are almost alone in challenging the EU over their censorship the heat is fully on them and they have to give a little. But I hope the feet dragging will encourage others to feet drag until such time as online freedom is restored.
Social media is the views of the public is it not? But ofcourse we have known for years that those views are being suppressed. So who do governments think they are to control the views of their citizens? People who say I believe in free speech but………”, don’t believe in free speech at all. ——-There are no “buts”.
It’s a pity that the disinformation Inquisition can’t develop a lisp. Diffinformation , everybody?
DSA = censorship by another name.
Only the authorities’ opinions will be allowed.
All other opinions will be deemed to be ‘mis(dis)information’.
This presumes the authorities are infallible, are never wrong and can never be criticized and scrutinized.