
This is a guest post by contributing editor Mike Hearn.
Last August, a cluster of fake scientific papers appeared in the journal Personal and Ubiquitous Computing. Each paper now carries a notice saying that it’s been been retracted “because the content of this article is nonsensical”.

This cluster appears to be created by the same group or person whom Daily Sceptic readers previously encountered in October. The papers are scientific-sounding gibberish spliced together with something about sports, hobbies or local economic development:
- “The conversion of traditional arts and crafts to modern art design under the background of 5G mobile communication network”, Linlin Niu
- “The application of twin network target tracking and support tensor machine in the evaluation of orienteering teaching”, Shenrong Wei
- “Application of heterogeneous execution body scheduling and VR technology for mimic cloud services in urban landscape design”, Liyuan Zhao
- “Application of deep and robust resource allocation for uncertain CSI in English distance teaching”, Li Junsheng
Therefore, the combination of LDPC and Polar codes has become the mainstream direction of the two technologies in the 5G scenario. This has further inspired and prompted a large number of researchers and scholars to start exploring and researching the two. In the development of Chinese modern art design culture, traditional art design culture is an important content…
Linlin Niu
This sudden lurch from 5G to Chinese modern art is the sort of text that cannot have been written by humans. Other clues are how the titles are obviously templated (“Application of A and B for X in Y”), how the citations are all on computing or electronics related subjects even when they appear in parts of the text related to Chinese art and packaging design, and of course the combination of extremely precise technical terms inserted into uselessly vague and ungrammatical statements about “the mainstream direction” of technology and how it’s “inspired and prompted” researchers.
An explanation surfaces when examining the affiliations of the authors. Linlin Niu (if she exists at all) is affiliated with the Academy of Arts, Zhengzhou Business University. Shenrong Wei works at the Department of Physical Education, Chang’an University. Li Junsheng is from the School of Foreign Studies, Weinan Normal University. Although the journal is a Western journal with Western editors, all the authors are Chinese, the non-computer related text is often to do with local Chinese issues and they are affiliated with departments you wouldn’t necessarily expect to be publishing in a foreign language.
The papers themselves appear to have been generated by a relatively sophisticated algorithm that’s got a large library of template paragraphs, terms, automated diagram and table generators and so on. At first I thought the program must be buggy to generate such sudden topic switches, but in reality it appears to be designed to create papers on two different topics at once. The first part is on whatever topic the targeted journal is about, and is designed to pass cursory inspection by editors. The second part is related to whatever the professor buying the paper actually “studies”. Once published the author can point colleagues to a paper published in a prestigious Western journal and perhaps cite it themselves in more normal papers, as ‘evidence’ of the relevance of whatever they’re doing to the high-tech world.
Prior events
If you’re a long-time reader of the Daily Sceptic, computer-generated gibberish being presented as peer-reviewed science won’t come as a surprise because this has happened several times before. Last year Springer had to retract 463 papers, but the problem isn’t restricted to one publisher. In July it was discovered that Elsevier had published a stream of papers in the journal Microprocessors and microsystems that were using nonsensical phrases generated from a thesaurus, e.g. automatically replacing the term artificial intelligence with “counterfeit consciousness”. This was not a unique event either, merely the first time the problem was noticed – searching Google Scholar for “counterfeit consciousness” returns hundreds of results spanning the last decade.
Computer-generated text is itself only the most extreme form of fake scientific paper. A remarkable number of medical research papers appear to contain Photoshopped images, and may well be reporting on experiments that never happened. Fake drug trials are even more concerning yet apparently prevalent, with a former editor of the BMJ asserting that the problem has become large-scale enough that it may be time to assume drug trials are fraudulent unless it can be proven otherwise. And of course, this is on top of the problem of claims by researchers that are nonsensical for methodological, statistical or logical reasons, which we encounter frequently when reviewing (especially) the Covid literature.
Zombie journals
Each time this happens, we take the opportunity to analyse the problem from a new angle. Last time we observed that journals appear to be increasingly automated, with the ‘fixes’ publishers propose for this problem being a form of automated spam filtering.
But why don’t these papers get caught by human editors? Scientific publishers like Springer and Elsevier appear to tolerate zombie journals: publications that look superficially real but which are in fact brain dead. They’re not being read by anyone, not even by their own editors, and where meaningful language should be there’s only rambling nonsense. The last round of papers published by this tech+sports group in the Arabian Journal of Geosciences lasted months before anyone noticed, strongly implying that the journal doesn’t have any readers at all. Instead they have become write-only media that exist purely so academics can publish things.
Publishers go to great lengths to imply otherwise. This particular journal’s Editor-in-Chief is Professor Peter Thomas, an academic with his own Wikipedia page. He’s currently affiliated with the “Manifesto Group”. Ironically, the content on the website for Manifesto Group consists exclusively of the following quote from a famous advertising executive:
People won’t listen to you if you’re not interesting, and you won’t be interesting unless you say things imaginatively, originally, freshly.
Bill Bernbach
This quote looks a bit odd given the flood of auto-generated ‘original’ papers Professor Thomas’s journal has signed-off on.
Clearly, he has never read the retracted articles given he later stated they were nonsensical. Instead, he blamed the volunteer peer reviewers for not complying with policy. And yet he isn’t on his own in editing this journal: the website lists a staggering 14 editors and 30 members of its international editorial board, which leads to the question of how not just one guy failed to notice they were signing off on garbage but all 45 of them failed to notice. For posterity, here are the people claiming to be editors yet who don’t appear to be reading the articles they publish:
Editors
Emilia Barakova, Eindhoven University of Technology, The Netherlands
Email: e.i.barakova@tue.nl
Alan Chamberlain, University of Nottingham, UK
Email: alan.chamberlain@nottingham.ac.uk
Mark Dunlop, University of Strathclyde, UK
Email: mark.dunlop@strath.ac.uk
Bin Guo, Northwestern Polytechnical University, China
Email: guobin.keio@gmail.com
Matt Jones, Swansea University, UK
Email: matt.jones@swansea.ac.uk
Eija Kaasinen, VTT, Finland
Email: eija.kaasinen@vtt.fi
Jofish Kaye, Mozilla, USA
Email: puc@jofish.com
Bo Li, Yunnan University, China
Email: boliphd@outlook.com
Robert D. Macredie, Brunel University, UK
Email: robert.macredie@brunel.ac.uk
Gabriela Marcu, University of Michigan, USA
Email: gmarcu@umich.edu
Yunchuan Sun, Beijing Normal University, China
Email: yunch@bnu.edu.cn
Alexandra Weilenmann, University of Gothenburg, Sweden
Email: weila@ituniv.se
Mikael Wiberg, Umea University, Sweden
Email: mwiberg@informatik.umu.se
Zhiwen Yu, Northwestern Polytechnical University, China
Email: zhiwenyu@nwpu.edu.cnInternational Editorial Board
Bert Arnrich, Bogazici University, Turkey
Tilde Bekker, Eindhoven University of Technology, The Netherlands
Victoria Bellotti, Palo Alto Research Center, USA
Rongfang Bie, Beijing Normal University, China
Mark Billinghurst, University of South Australia, Australia
José Bravo, University of Castilla-La Mancha, Spain
Luca Chittaro, HCI Lab, University of Udine, Italy
Paul Dourish, University of California, USA
Damianos Gavalas, University of the Aegean, Greece
Gheorghita Ghinea, Brunel University, UK
Karamjit S. Gill, University of Brighton, UK
Gillian Hayes, UC Irvine, USA
Kostas Karpouzis, National Technical University of Athens, Greece
James Katz, Boston University, USA
Rich Ling, Nanyang Technological University, Singapore
Patti Maes, MIT Media Laboratory, USA
Tom Martin, Virginia Tech, USA
Friedemann Mattern, ETH Zurich, Switzerland
John McCarthy, University College Cork, Ireland
José M. Noguera, University of Jaen, Spain
Jong Hyuk Park, Seoul National University of Science and Technology (SeoulTech), Korea
Francesco Piccialli, University of Naples “Federico II”, Italy
Reza Rawassizadeh, Dartmouth College, USA
Enrico Rukzio, Ulm University, Germany
Boon-Chong Seet, Auckland University of Technology, New Zealand
Elhadi M. Shakshuki, Acadia University, Canada
Phil Stenton, BBC R&D, UK
Chia-Wen Tsai, Ming Chuan University, Taiwan
Jean Vanderdonckt, LSM, Université catholique de Louvain, Belgium
Bieke Zaman, Meaningful Interactions Lab (Mintlab), KU Leuven, Belgium
What are academic outsiders meant to think when faced with such a large list of people yet also evidence that none of them appear to be reading their own journal? Does editorship of a scientific journal mean anything, or is this just like the Chinese papers – another way to pad resumés with fake work?
We may be tempted for a moment to think that as the papers were after all retracted, perhaps at least some of them are checking? But putting aside for a moment that an editor is meant to do editing work before publishing, from a quick flick through their most recent papers, we can see that nonsensical and irrelevant work is still getting through. For example:
- “Analysis of investment effect in Xinjiang from the perspective of nontraditional security“, which has nothing to do with personal computing. Instead it’s about China’s efforts to crack down on the ethnic Muslim population in Xinjiang. Abstract: “Terrorism poses a huge threat to economic development. Based on the data of terrorist activities provided by the Global Terrorism Database, this paper analyzes the temporal and spatial characteristics of terrorist activities in Xinjiang”. Amusingly, one of the author’s affiliations is literally stated as the “Research Center On Fictitious Economy and Data Science”.
- “Synergic deep learning model-based automated detection and classification of brain intracranial hemorrhage images in wearable networks“, which briefly mentions “wearable technology products” (e.g. Apple Watch) before going on to talk about automatically classifying CT scans in hospitals. The latter has nothing to do with the former.
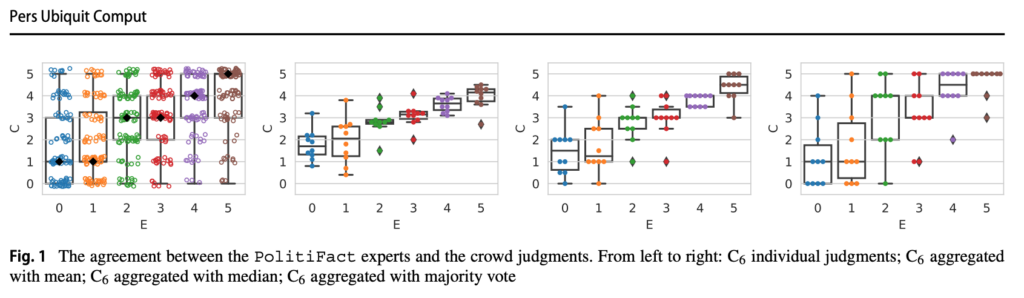
Perhaps inevitably, this journal has also published “Can the crowd judge truthfulness? A longitudinal study on recent misinformation about COVID-19“. This is one of a series of studies that asks pay-per-task workers on Amazon Mechanical Turk (defined as “the crowd”) to answer questions about Covid and U.S. politics. Their answers are then compared to the “ground truth” of “expert judgements” found on … Politifact (see chart below). As well as being irrelevant to the journal, this exemplar of good science had a sample size of just 10 survey takers despite requiring a team of nine academics and support “by a Facebook Research award, by the Australian Research Council, by a MIT International Science and Technology Initiatives Seed Fund and by the project HEaD – Higher Education and Development – (Region Friuli – Venezia Giulia)”. The worthlessness of their effort is, naturally, used as a justification for doing it again in another paper – “having a single statement evaluated by 10 distinct workers only does not guarantee a strong statistical power, and thus an experiment with a larger worker sample might be required to draw definitive conclusions”.
Root causes
The goal of a scientific journal is, theoretically, to communicate new scientific discoveries. The goal of peer review is to create quality through having people (and especially competitors) carefully check a piece of work. And rightly so – many fields rely heavily on peer review of various kinds, including my own field of software engineering. We do it because it finds lots of mistakes.
Given these goals, why does Springer tolerate the existence of journals within their fold that repeatedly publish auto-generated or irrelevant articles? Put simply, because they can. Journals like these aren’t really read by normal people looking for knowledge. Their customers are universities that need a way to define what success means in a planned reputation economy. Their function has been changing – no longer communication but, rather, being a source of artificial scarcity useful for establishing substitute price-like signals such as h-indexes and impact factors, which serve to bolster the reputations and credentials of academics and institutions.
This need can result in absurd outcomes. After a long campaign to make publishing open access (i.e., to allow taxpayers to read the articles they’ve already funded) – to its credit largely by scientists themselves – even that giant of science publishing Nature has announced that it will finally allow open access to its articles. The catch? Scientists have to pay them $10,000 for the privilege of their own work being made available as a PDF download. In the upside down world of science, publishers can demand scientists pay them for doing little beyond picking the coolest sounding claims. The actual review of the article will still be done by volunteer peer reviewers. Yet some of them will pay because the money comes from the public via Government funding of research, and because being published in Nature is a career-defining highlight. In the absence of genuine market economics tying research to utility, how else are they meant to rank themselves?
Meanwhile, peer review seems to have become a mere rubber stamp. The label can well mean a genuinely serious and critical review by professionals was done, but it might also mean nothing at all, and it’s not obvious how anyone is meant to quickly determine which it is. The steady decay of science into random claim generation is the inevitable consequence.
The author wishes to thank Will Jones and MTF for their careful peer review.
Mike Hearn is a former Google software engineer and author of this code review of Neil Ferguson’s pandemic modelling.











To join in with the discussion please make a donation to The Daily Sceptic.
Profanity and abuse will be removed and may lead to a permanent ban.
Aren’t Budweiser sponsoring this geezer as well.
Sort of ironic, fake beer for a fake women.
Geezer, Yes!
Not bowing to the thought police.
Nor am I.
Kid Rock perhaps says it for us?
https://www.youtube.com/watch?v=JZ19c16nZOQ
Plus I think Candace Owens nails it…!
Apparently they lost $800 million of market cap value as their shares nose-dived.
Nike. Me no likey.
Really like what Jessica Rose has to say on what the definition of a woman is and the whole trans ideology thing coming at us from all angles;
”I want to now transiently examine the ‘transgender movement’ (‘activists’) and the way in which, well, the movement (not to be confused with individuals) is pretty much being shoved in our faces and down our throats at every turn lately – and not just on social media. This ‘movement’ is appearing in public settings and even more disturbing to me, in strange and inappropriate settings that are aimed at children. I am seeing a lot of irrational violence associated with these so-called activists, as well.
These ‘movements’, among many things, are tricks – imposed propaganda-style – to try to convince you that we’re all separate, different and in a big stupid constant fight. We’re not. Don’t fall for it. War gamers are devious. And their pawns are clueless. See them for what they are. Many of the victims of these tricks are the young. They need good role models and good guidance. Away from predators. It’s always been like this. Be a good role model.
Ultimately my philosophy is this, do what you want, but don’t shove it in my face and tell me I have to like it or even put up with it. Especially if you’re preying on children. I have fought bullshit my entire life and I am not stopping now. I am woman. Hear me roar. And as much as many people would like to pretend that there are no lines to cross: THERE ARE.
So what is a woman? I am a woman: an adult female human being carrying two X chromosomes.”
https://jessicar.substack.com/p/i-can-define-what-a-woman-is
At a school recently, someone gave a talk about freedom of speech and gave as an example of freedom of speech the freedom from coercion to call people by chosen pronouns. In other words, freedom of speech entailed not being forced to use a pronoun just because someone demanded it.
The reaction afterwards:, on the whole, the boys thought it.made.perfext sense and the girls were appalled and thought the speaker was a transphobe.
There is something that those who want to make this an assault on women are missing and that is that this ideology is most appealing now to teenaged girls.
Until that is paid attention to, understood why and addressed the problem is just going to get worse.
I think you make a very good point. Perhaps the girls’ interest and support is linked to a reaction to the girly girl porn style which was offered to little girls until quite recently (all clothes pink and purple, glitter and stars for toys) and a return to a sort of tom boy option that many of us leaned towards when we were growing up (think Famous Five – George was one type of girl and Ann another). If you want to hide your sexuality at school and not be the object of boys unwanted attention then perhaps now young girls choose to hide behind the trans idea.
Watching France 24 recently when abroad I was very intrigued to see that in a piece about Drag in France they also interviewed a Drag King – woman with painted on black moustache – who made the point that this is just/still the patriarchy in a new version which women are not allowed to object to because it is “unfair”. A very valid observation.
That’s a very fair point. I agree over sexualisation of women and young girls in particular is very corrosive.
I would just point out that much of the pressure on women comes from other women. At least that is what I’ve heard many say.
The advertising and entertainment industry doesn’t help at all obviously. It’s a bad cocktail.
Not surprising. Wimmin have been forcing down our throats their World view of their eternal fight against the Patriarchy, toxic masculinity, I’m a Ms not a Miss, women and men are equal – but not in sport apparently – women should have access to men’s spaces, but woman should have spaces reserved just for them.
It’s natural that the little, maids would identify with fellow victims.
“Movement” used to refer to bowels.
And the product.
Just read this … excellent and beautifully written … thanks for the pointer.
This is really a come to Jesus moment for feminism.
After decades of flirting with the notion that the differences in behaviour and outcomes between men and women are not biological but socially constructed, the idea has gone half a step further and spawned an ideology in which gender is a social construct. Men can chose to be women at any time and vice versa. Why not, they’re basically the same, right?
Feminism has spun out of control and we now have a new ideology, even more hateful, destructive and insane.
How to get the cat back in the bag.
I’m pretty sure that more feminist self victimisation is not the answer. Men, especially young boys being bludgeoned with this ideology in schools, are equally being assaulted by this madness.
Sorry, are we reading the same thing? Sharon Davies, who I suspect considers herself to be a feminist and standing in defence of the integrity of actual women…..is the one asking people to boycott Nike…
Dylan Mulvaney is a man..the President and CEO of Nike is a man …the eight most senior executives behind him are men.
Dylan Mulvaney also advertises Bud Light…. The president and CEO of Anheuser Busch is a man….there are 15 executives in the ‘Leadership Team’…14 of them are men….….…..
…….and femenists have a problem?
As usual I don’t recognise any women I know as the type of ‘feminists’ you always describe…..Where the hell do you meet these women?
So men bad, woman good? Gotcha.
Ebygum was simply stating the facts about who is making decisions in those companies. Your response seems to say more about where you are coming from than anything else.
Point …missed..whoosh!!
Yes and I’ve given examples of women driving this too.
It’s complex.
Large corporations are adopting climate nonsense and the whole woke agenda for very devious reasons. They are forming a coalition with their biggest traditional enemy, the far left, who would normally be after them for being capitalists, but because then left is now all about climate change and wokism, they’ve become allies.
So companies can continue to make enormous profits and expand their power with the support of the left, as.long as they play the woke game.
Some feminists like Sturgeon or those crazy Kansas women law makers are pro-trans agenda. Others, like Rowling, are against.
And that is basically like Sunni vs Shia or Catholics vs Protestants. The trans agenda is basically the radicalisation of the feminist agenda.
That’s how I see it. And that would explain how teenage girls are so for trans rights, why teachers unions are for trans rights, why the teaching profession as a whole, so dominated by women, is allowing its.proliferation in schools and how radical feminists like Sturgeon are for it too.
The problem of trans ideology needs to be understood properly, not superficially, from news headlines.
I don’t consider Sturgeon to be a feminist of any sort … she’s an awful person, in every way, and just clearly following the nutty agenda..you seem to think all women are feminists, particularly the bad ones. They aren’t….
it’s just a label you smear most women with…as in your other post you think women are to blame for the notion that “the differences in behaviour and outcomes between men and women are not biological but socially constructed”…good one, except which women are these, as I don’t know any that would agree with that sentence?
And as it’s men..being trans-women, who are making all the fuss, and expecting the rules to be changed for them???
There are as many men involved in this as women, so what are we going to call them..radical misogynists? Every time these stories crop up shall we just blame it on the radical misogynists?…it is after-all about trans women..who are biologically male….not the other way around..
Yes it’s a big subject, yes it’s more complex, but the issue in this report is that trans-men are being ‘favoured’ over actual women…
…trans-women are infiltrating women’s spaces, which means women can’t feel safe in jails, hospitals or any ‘shared space’….trans women are invading women’s sport…Fallon Fox, the MMA fighter, and a trans-woman, has just fractured the skull of a second female opponent…..and while it might be a side show to you, it’s very real to the women involved…
You’ll notice I don’t bring up women or feminism in any other context other than the trans problem. So, no, despite your insistence I am not a misogynist. It’s simply that current trans ideology has its origins in feminism and I’m calling it out, not to have a go at women or any nonsense like that but because I want the problem solved.
Just because you don’t consider Sturgeon a feminist doesn’t mean she isn’t. She thinks she is and says so. Just because you don’t recognise the feminism I describe it doesn’t mean it doesn’t exist and it doesn’t mean it doesn’t have enormous influence on the social discourse. It does exist and the influence of more extreme feminist views is clear.
How many people believe in extreme gender ideology, male or female? Few. And yet there you have the results affecting our society very profoundly. With organisation, influence, funding, powerful allies and zeal few people can accomplish a lot.
I’ll repeat, having to make this point over and over again is like trying to get the idea of “safe and effective” out of the mind of someone who thinks modern medicine is one of humanity’s greatest achievements and that our medical establishment would never do that to us.
I have never said you are misogynist..just asking why women you think are guilty have a name and the men don’t?
I don’t agree that trans ideology comes from the original genuine feminism that I know and believe in. So we won’t ever agree on that…and I would say, as it seems to be your ‘safe and effective’ mantra..you have the problem, not me.
The expansion of trans rights has gone more in hand with state and institutional regulation of speech and behaviour….not just in relation to women and men but calling Welsh people Taff, or people of colour certain names, or calling gay people ‘poofs’ etc…not having hot-cross buns…because?…..celebrating Eid, but not St George’s day…etc…etc…this has been going on for years, and this is sadly an extension of it in my opinion…
…..and even though the trans lobby are small, people in positions of power…(just as many of them men) in the media, academia, law, the medical profession, police, Government both local and National have gathered around the ‘cause’….and now try to legislate the behaviours of all of us, rather than that tiny minority…
The why is something I don’t know….
I don’t know if you have read Lindsay and Pluckrose’s analysis of feminism, gender studies, queer theory with marxist and postmodern influences, in their ‘Cynical Theories‘? They trace the evolution of marxist feminism modified with queer theory and postmodern Derridean analysis of language to deconstruct the meanings of “man and “woman” whereby a dominant view within marxist feminism had it that “man” and “woman” were to be regarded as “constructions or representations – achieved through discourse, performance and repetition – rather than real entities”(P141).
The shift away from sex to gender was documented in Candace West and Don H Zimmerman’s 1987 paper Doing Gender in which they have a shift away from sex and towards gender, they “explicitly reject biology as a source of differences in male and female behaviours, preferences or traits”(P147)
This change was documented in a 2006 essay by Judith Lorber and followed up by further accounts of gender studies coming out of that by Judith Pilcher and Imelda Whelan ‘Key Concepts in Gender Studies’ 2017.(P144).
The page numbers refer to Lindsay and Pluckrose’s book.
Needless to say, coming out of STEM, I find this wild theorising coupled with reification utterly fascinating – and frightening.
Lindsay and Pluckrose also look at liberal feminism also diverting into intersectional or diversity feminism concerned with identity.
I am interested to know why you clearly take feminism so personally.
I don’t take it personally. I think the trans problem is being completely misrepresented and misunderstood.
Some women are trying to male this about them, a new form of misogyny. But it isn’t. The men in women’s loos and women’s sports is a sideshow. The real problem and danger is in schools. Driven by women, and taken up mostly by men.
If you aren’t involved in schools in some way you probably aren’t seeing it. But it’s a dangerous problem.
And it is linked to feminism. Its a kind of spin off from it. It appeals to many ultra.feminists and to teenage girls.
I always thought the point of support bras was for support.
I am looking forward to seeing Nike’s advert for jock straps.
It’s just nonsense, but so very few seem brave enough to say so.
My lady is fairly busty and a sports bra holds everything still while she’s active. I’m told they’re quite heavy and without one exercise would be painful for her.
Dylan’s plainly a boy, with (a pathetic attention-seeking complex and…) nothing whatsoever that requires the support of a sports bra. No matter what the activity nothing will bounce and nobody will know if the garment works or not.
I doubt he’s likely to get the snip, I hear that not many do – that requires true commitment and bravery. But if he does, then he can also model the jock strap for Nike and demonstrate it’s ability to hold a load of absolute bllx
Maybe we need to set up a truss fund.
Old news. Anyone with a moral compass will have been boycotting Nike since they started paying professional knee taking and perpetually whingeing victim Colin Kapernick to promote their sweat shop output.
Wasn’t Nike a goddess?
Yes..the Goddess of victory…I saw her beautiful statue in Warsaw once….
but you know, myth, history, stories…it can all be re-written can’t it?
People like an easy lie rather than the hard truth these days….
This makes perfect sense for the fashion industry, I don’t know why they didn’t think of using trans models to replace women sooner instead of forcing women to starve themselves to be a boyish shape. I always assumed the fashion houses needed women to be emaciated because they weren’t talented enough to design clothes to fit female curves. Nike has proved you don’t have to worry any more.
Is a boycott really necessary? Seems like Nike are sh*tting in their own nest.
One could easily form the opinion that Nike does not know or care about the difference between sexes. As a sports ware brand (I almost write in error “manufacturer”) one would have thought they knew the difference.
What next, Buck Angel being sponsored to advertise jock straps?
Another entity added to me ‘boycott’ list – from Paypal to Walkers crisps, to Penquin Books, the list just keeps expanding. Helping me save.
Matt Walsh is making the point that the mass boycotting you refer to is ineffective. Better to ‘flash’ target woke companies one by one, starting with Anheuser Busch. A list of their products … https://twitter.com/Travistritt/status/1643773257206693888
Thank you Nike for telling the female population that a man without breasts who tells you he is a woman is so much better at being a woman than the real thing.
In order to prove that you as a company actually believe in this “its what you say you are rather than what biology says” When can we expect to see a white person dressed as a black man rather like the minstrel show from the 70’s used in one of your ads for sports gear? After all if a man can profess to be a woman and its not allowed to be offensive to real women, surely a white person can put black make up on, claim to be black and it not be considered acceptable for black people to find it offensive.
So go on show us just how serious you are and not just a craven money grabbing go along with anything for the cash company
spot-on Hester…
An excellent suggestion
It is up to each individual ofcourse, but I will never purchase from any company that tries to stuff any ideology down my throat. The woke capitalists will not get any of my money if I can help it. I already asked my wife not to buy any DOVE products because of their TV ads that have black women in business suits staring in utter contempt at the camera. But when you take a look at TV ads these days all they seem to care about is putting as many different races on the screen as they can stuff in there. If a husband is white his wife will be black and vice versa. It seems these days that the woke capitalists pretend that they care about something other than profit and power precisely to gain more of both.
Seems to me that the black and other coloured people in tv ads and programmes are indicative of a slave market emerging to make up the numbers for an ever reducing pool of suitable, willing but unambitious white actors and actresses.
Well done Nike, for showing us that your sports bras are absolutely crap and not fit for purpose: you’ve had to use a flat chested bloke to advertise them! Great job.
It’s very difficult to argue with the logic of that argument.
Is it just me, but Dylan looks a bit like a brave little toaster, dancing around with a rictus grin, pretending everything is fine, when they are dying inside ?…
..plus he’s a funny looking little gink! LOL!
Fake beer, fake America, crap expensive shyte, made in Indian! Go campaign for sales there! Bunch of f-ing idiots!
Put your cock where your mouth is and get it cut off! Then I might believe you, freak
Not sports bra’s, Breast binding! Why doesn’t…it..bind its head and feet too? and then p*#s off!
Products to abandon!
Nike
Budweiser Family
•Budweiser
•Bud Light
•Budweiser Select
•Budweiser American Ale
•Bud Dry
•Bud Ice
•Bud Ice Light
•Budweiser Brewmaster Reserve
•Bud Light Lime
•Budweiser & Clamato Chelada
•Bud Light & Clamato Chelada
•Bud Extra
– Michelob Family
•Michelob
•Michelob Light
•Michelob Honey Lager
•Michelob AmberBock
•Michelob Golden Draft
•Michelob Golden Draft Light
•Michelob Bavarian Wheat
•Michelob Porter
•Michelob Pale Ale
•Michelob Dunkel Weisse
– Ultra Family
•Michelob Ultra
•Michelob Ultra Amber
•Michelob Ultra Lime Cactus
•Michelob Ultra Pomegranate Raspberry
•Michelob Ultra Tuscan Orange
– Busch Family
•Busch
•Busch Light
•Busch Ice
– The Natural Family
•Natural Light
•Natural Ice
– Specialty Beers
•Bud Extra
•Bare Knuckle Stout
•Anheuser World Lager
•ZiegenBock
•Ascent 54 (Colorado only)
•Redbridge (gluten-free)
•Rolling Rock
•Landshark Lager
•Shock Top
•Skipjack Amber Lager
•Wild Blue
– Seasonal Beers
•Sun Dog (spring)
•Beach Bum Blonde Ale (sum)
•Jack’s Pumpkin Spice Ale (fall)
•Winter’s Bourbon Cask (wntr)
– Non-alcoholic
•O’Doul’s
•O’Doul’s Amber
•Busch NA
•Budweiser NA
•Budweiser NA Green Apple
– Energy Drinks
•180 Blue
•180 Sport Drink
•180 Energy
•180 Red
•180 Blue Low Calorie
•180 Sugar Free
– Specialty Organic Beers
•Stone Mill Pale Ale
•Wild Hop Lager
– Specialty Malt Beverages
•Bacardi Silver
•Peels
•Tequiza
•Tilt
Also Stella Artois
Weak fizzy p*ss each and every one of them. & almost certainly turning boys and men into women and girls due to the hideously unnatural ingredients.
People who drink these products will not live long and happy lives. The manufacturers know it. The whole thing is based on contempt for customers and profiteering. See vaccines.
(
 weak fizzy p*ss!
weak fizzy p*ss! 
 )
)
You are so right ️
️
I’m mad Jack Daniels has joined the ‘in crowd’ as well as I always liked it …luckily I’ve discovered Buffalo Trace….LOL!
There’s always an alternative!!
This is what Ted Nugent and Kid Rock think of the Bud Light et al campaigns. Definitely worth a watch…
https://youtu.be/ipElQEzsWKs
Brilliant…I put the Kid Rock on earlier, but the more the merrier and I like Ted Nugent…’truth, logic and common sense is Kryptonite to our governments, media and big tech’… absolutely….!
Since I don’t and never have bought a Nike product, and in any case likely never would, I find myself unable to boycott them.
How annoying.
There’s an American YouTube channel I occasionally watch where the presenter was commenting on the latest school shooting.
The assassin / terrorist was trans so he suggested that their pronouns should now be “was” and “were”.